")
")

Аннотация
В последнее время концепция взаимодействия между людьми и роботами вызвала множество научных интересов. Вместо того, чтобы роботы заменили рабочих-людей на рабочих местах, сотрудничество человека с роботами - это направление, позволяющее сохранить рабочие места, организовав возможность роботам и людям работать вместе. Сотрудничество между людьми и роботами может освободить людей от тяжелых задач, если будут созданы эффективные каналы связи между людьми и роботами. Хотя каналы связи между людьми и роботами по-прежнему ограничены, распознавание жестов эффективно применяется в качестве интерфейса между людьми и компьютерами в течение длительного периода времени. Помимо описания ряда важных технологий и алгоритмов распознавания жестов, в этой статье представлен обзор исследований распознавания жестов и изучения возможности применения распознавания жестов во взаимодействии человека и робота. В этой статье также предлагается общая модель распознавания жестов для взаимодействия человека и робота. В модели распознавания жестов для взаимодействия человека и робота есть четыре основных технических компонента: сенсорные технологии, идентификация жестов, отслеживание жестов и классификация жестов. Рассмотренные подходы классифицируются в соответствии с четырьмя основными техническими компонентами. Статистический анализ представлен после технического анализа. В последней части обзора намечены будущие направления исследований.
Статья впервые опубликована в Королевском Технологическом Институте KTH, Департаментом производственной инженерии (Стокгольм, Швеция)
Источник (оригинал): researchgate.net
Дата публикации: 01 октября 2017 года.
Переводчик: Поткин Олег.
1. Вступление
1.1. Взаимодействие человека и робота
Роботизированные системы уже стали ключевыми компонентами в различных отраслях промышленности. В последнее время концепция Human-Robot Collaboration (далее HRC) значительно подогрела исследовательские интересы. Литературные примеры предполагали, что работники-люди обладают несравненными навыками решения проблем и сенсорно-двигательными способностями, но имеют ограниченную силу и точность [1, 2]. Однако роботизированные системы имеют высокую стойкость к усталости, скорость, повторяемость и лучшую производительность, но они ограничены в гибкости. HRC может освободить работников-людей от тяжелых задач и устанавливать каналы связи между людьми и роботами для повышения общей эффективности.
В идеале связка (команда) HRC должна работать так же, как человеческая совместная команда. Тем не менее, традиционно методы разделения времени или пространственного разделения применяются в системах HRC, что снижает производительность как для рабочих, так и для роботов [1]. Чтобы создать эффективную команду HRC, в качестве примеров можно проанализировать группы сотрудничества человека с человеком. В совместной работе и сотрудничестве людей существует две теории: теория совместных намерений и теория обучения [3-6]. Чтобы применить теории в команде HRC, существует три опытных подхода, которые приносят пользу команде HRC:
-
Все члены команды в команде HRC должны иметь один и тот же план исполнения;
-
Все члены команды в команде HRC должны знать контекст среды совместной работы; а также
-
Команда HRC должна иметь структурированные способы общения.
В этой статье основное внимание уделяется третьему пункту, т. е. структурированным способам коммуникации.
1.2. Распознавание жестов
Жесты – один из способов общения. Мимика, жесты рук и позы тела являются эффективными каналами связи в человеко-человеческом сотрудничестве [2, 7]. Жесты могут быть разделены на три типа [8]:
-
Жесты тела: действия или движения всего тела;
-
Жесты рук и кистей рук: позы рук, жесты рук;
-
Головные и лицевые жесты: кивания или вращения головы, подмигивая, губы.
Распознавание жеста относится к математической интерпретации человеческих движений вычислительным устройством. Чтобы взаимодействовать с человеком, роботы должны правильно понимать человеческие жесты и действовать в соответствии с жестом в достаточной степени точности. В среде HRC должен быть доступен естественный способ коммуникации между роботами и людьми.
1.3. Распознавание жестов для человеко-машинного взаимодействия (HRC)
Чтобы распознать жесты в контексте HRC, полезно исследовать общую и упрощенную модель обработки информации. Как показано на Рис. 1, Parasuraman представил [9] обобщенную модель обработки информации, состоящую из четырех этапов. На основе общей модели, показанной на Рис. 1, предлагается конкретная модель распознавания жестов в HRC. Как показано на Рис. 2, существует пять основных частей, связанных с распознаванием жестов для HRC: сбор данных с датчиков, идентификация жестов, отслеживание жестов, классификация жестов и отображение жестов.

Рис. 1. Четырехступенчатая модель обработки информации [9]: сбор данных, анализ данных, принятие решения, отклик.
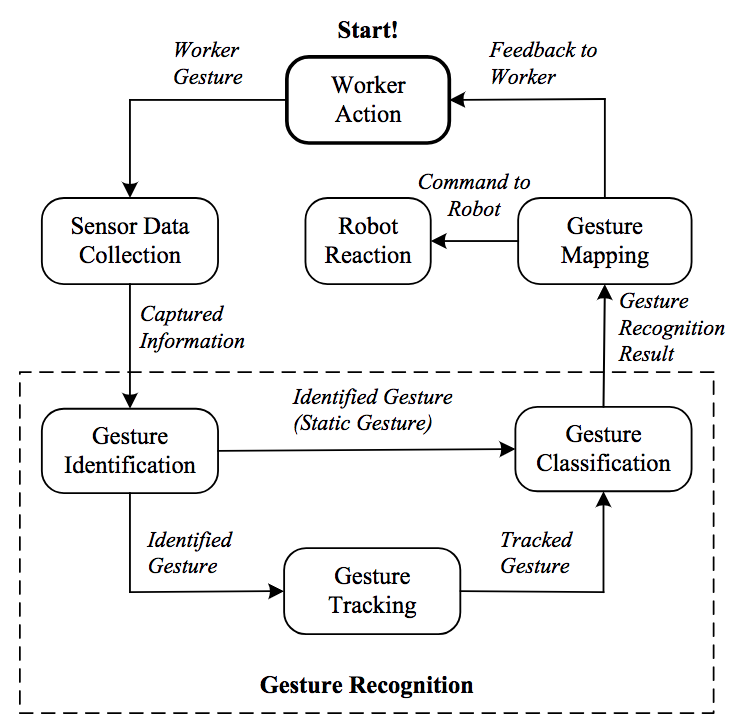
Рис. 2. Модель процесса распознавания жестов при взаимодействии человека и робота.
-
Сбор данных с датчиков: жестовые данные фиксируются датчиками.
-
Идентификация жеста: в каждом фрейме жест отображается из необработанных данных.
-
Отслеживание жеста: локализованный жест отслеживается во время движения. Для статических жестов отслеживание жестов не требуется.
-
Классификация жестов: отслеживание движения жестов классифицируется в соответствии с заранее определенными типами жестов.
-
Отображение жеста: результат распознавания жестов преобразуется в управляющие команды.
Статья организована следующим образом: в разделе 2 рассматриваются технологии сенсорных датчиков. В разделе 3 представлен обзор методов идентификации жестов. В разделе 4 обсуждаются проблемы отслеживания жестов. Раздел 5 описывает алгоритмы классификации жестов. В разделе 6 показан статистический анализ рассмотренных работ. В разделе 7 описывается работа над будущими направлениями исследований.
2. Сенсорные технологии
Перед процессом распознавания жестов рабочие данные должны быть собраны датчиками. В этом разделе датчики анализируются на основе различных технологий захвата данных. Как показано на Рис. 3, существуют две основные категории сбора данных: основанные на изображениях и не основанные на изображениях.
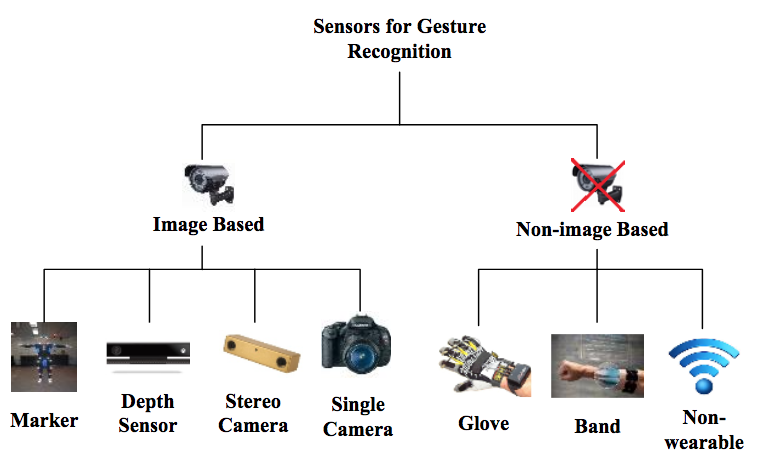
Рис. 3. Различные типы датчиков распознавания жестов.
2.1. Метод на основе получения изображений
Технологии часто вдохновляются природой. Мы используем наши глаза, чтобы распознавать жесты. Поэтому для роботов разумно использовать камеры, чтобы «видеть» жесты. Подходы, основанные на работе с изображениями, далее подразделяются на четыре категории.
-
Маркер
В маркерном подходе датчиком является оптическая камерой. В большинстве решений на основе маркеров пользователям необходимо носить видимые маркеры [8]. Сегодня мы получаем гораздо более быструю графическую обработку по сравнению с двадцатью годами ранее. В результате на рынке доступно множество датчиков распознавания жестов.
-
Камера
В начале 90-х годов исследователи начали анализировать жесты при помощи одиночной камеры [10, 11]. Недостатком однокамерного подхода является ограничение угла обзора, что влияет на надежность системы [12]. Однако в недавних исследованиях применялся однокамерный подход к высокоскоростному распознаванию жестов [13]. Система использует датчик скорости и специально разработанный процессор визуальных вычислений для достижения высокоскоростного распознавания жестов.
-
Стереокамера
Чтобы добиться надежного распознавания жестов, исследователи предложили стереоподход к созданию 3D-зрения. Здесь мы определяем стереокамерные подходы как приложения, которые используют две оптические камеры для создания информации о глубине 3D. Многие стереоподходы к камерам соответствовали аналогичному процессу [14, 15]. Хотя системы стереокамер улучшили устойчивость во внешней среде, они по-прежнему страдают от таких проблем, как сложность вычислений и трудности с калибровкой [16].
-
Сенсор глубины
В последнее время технологии глубокого зондирования быстро развиваются. Мы определяем датчик глубины как моно-датчик глубины. Моно-датчики глубины обладают рядом преимуществ по сравнению с традиционными стереокамерами. Например, можно предотвратить проблемы настройки калибровки и условий освещения [17]. Кроме того, выходной информацией датчика глубины является информацией о глубине 3D. По сравнению с информацией о цвете информация о глубине 3D упрощает проблему идентификации жестов [8]. Сравнение точности идентификации жестов с использованием информации о цвете и глубине можно найти в [18]. Существует два типа общих не стерео-датчиков глубины: камера с «временем пролета» (ToF) и Microsoft Kinect (или аналогичные ИК-датчики).
Основным принципом камер ToF является определение времени прохождения света [19]. В различных публикациях были введены примеры распознавания жестов на основе ToF-камер [18, 20]. Преимуществом камер ToF является более высокая частота кадров. Ограничение камеры ToF заключается в том, что разрешение камеры сильно зависит от ее светочувствительности и рефлексии [21].
Microsoft Kinect предоставляет дешевое и простое решение для распознавания жестов. Kinect - инфракрасный датчик глубины. Аналогичными датчиками являются ASUS Xtion Pro и Apple PrimeSense. Kinect имеет ИК-излучатель, ИК-датчик и датчик цвета. Он широко используется в сфере развлечений, образования и исследований с большим сообществом разработчиков [22-24]. Доступно множество инструментов и проектов с открытым исходным кодом. Некоторые исследователи реализовали системы распознавания жестов на основе Kinect на коротких расстояниях [25-27]. Из-за ограниченного разрешения, в настоящее время Kinect может использоваться для распознавания жестов тела и распознавания жестов рук на небольшом расстоянии. Для распознавания жестов рук и кистей рук на расстоянии более 2 метров лучше использовать другие подходы.
2.2. Методы, основанные не на изображениях
В распознавании жестов в течение долгого времени доминировали датчики на основе изображений. Недавние разработки в MEMS и сенсорных технологиях значительно улучшили технологии распознавания жестов, основанные не на изображениях.
-
Перчатки
Жестовые интерфейсы на основе перчаток также используются для распознавания жестов. Обычно методы на основе перчаток требуют проводного подключения акселерометров и гироскопов. Однако громоздкая перчатка с проводами может вызвать проблемы в HRC [8, 28]. Подходы на основе перчаток также имеют сложности в процедурах калибровки и настройки [29].
-
Браслет (носимая электроника)
Другая бесконтактная технология использует сенсоры на браслетах. Сенсоры установлены на браслете или аналогичных носимых устройствах. Сенсоры на браслетах позволяют использовать беспроводные технологии и датчики электромиограммы, что позволяет избежать подключения кабелей. Сенсоры должны контактировать с запястьем; руки и пальцы пользователя могут быть свободны. Примером браслетного датчика является устройство Myo [30]. Недавно были опубликованы несколько систем жестового управления на основе браслетов [31-33].
-
Бесконтактные устройства
В третьем типе технологий, не связанных с изображениями, используются датчики, не предназначенные для ношения. Бесконтактные датчики могут обнаруживать жесты без контакта с человеческим телом. Google представил Project Soli, систему радиолокационного контроля и распознавания жестов на радиочастотном спектре (радар) [34]. Устройство способно распознавать разные жесты рук на небольшом расстоянии. В течение многих лет MIT является ведущим новатором в области распознавания жестов. Технология электрического поля была впервые разработана в MIT [35]. Недавно Adib [36-38] из MIT представил систему WiTrack и RF-Capture, которая отслеживает движение пользователя по радиочастотным сигналам, отраженным от человеческого тела. Система способна захватывать человеческие жесты даже из другой комнаты через стену с точностью до 20 см. Таким образом, технологии, не пригодные для ношения, являются перспективными и быстрорастущими сенсорными технологиями для распознавания жестов.
2.3. Сравнение сенсорных технологий
Таблица 1 содержит сравнение различных сенсорных технологий. Показаны преимущества и недостатки различных подходов. Понятно, что ни один датчик не подходит для всех приложений. На основе вышеуказанных методов представлены два вида сенсорных технологий:
-
Сенсоры для использования внутри помещений: датчики глубины являются наиболее перспективными технологиями на основе изображений. Датчики глубины обладают преимуществами простоты калибровки, установки и скорости обработки данных. Существует большое сообщество разработчиков приложений, которое предоставляет готовые решения.
-
Бесконтактные сенсоры являются наиболее перспективной технологией среди подходов, основанных не на изображении. Они не требуют прямого контакта с пользователями. Эта категория сенсоров также является быстрорастущей отраслью на рынке технологий.
Таблица 1. Достоинства и недостатки различных сенсорных технологий
|
|
Достоинства |
Недостатки |
|
Маркеры |
Низкая вычислительная нагрузка |
Маркеры на теле пользователя |
|
Камера |
Простота установки |
Низкий уровень надежности |
|
Стереокамера |
Надежность |
Сложность вычислений, трудности с калибровкой |
|
ToF камера |
Высокая частота кадров |
Разрешение зависит от мощности света и отражения |
|
Microsoft Kinect |
Поддержка программного обеспечения для распознавания жестов тела |
Невозможно использовать для распознавания жестов руки на расстоянии более 2 метров |
|
Перчатка |
Скорость отклика, точность трекинга |
Громоздкое устройство с проводами |
|
Браслет (сенсоры на базе браслета, носимая электроника) |
Скорость отклика, область действия |
Браслет должен контактировать с человеческим телом |
|
Бесконтактные устройства |
Не требует контакта с телом |
Низкое разрешение, технология недостаточно зрелая |
3. Идентификация жестов
Идентификация жеста - первый шаг в процессе распознавания жестов после получения необработанных данных, полученных с датчиков. Идентификация жеста означает обнаружение жестовой информации и сегментацию соответствующей жестовой информации из необработанных данных. Популярные технологии для решения проблемы идентификации жестов основаны на визуальных особенностях, алгоритмах обучения и человеческих моделях.
3.1. Визуальные характеристики
Человеческие руки и тело обладают уникальными визуальными особенностями. В распознавании жестов на основе изображений жесты состоят из фрагментов человеческих рук и/или тела. Поэтому использование таких визуальных признаков в идентификации жестов вполне обоснованно.
-
Цвет
Цвет – это простая визуальная функция для идентификации жестов из фоновой информации. Однако на системы распознавания жестов на основе цветов сильно влияют освещение и тени в сложной среде HRC [39]. Еще одна распространенная проблема в обнаружении цвета кожи заключается в том, что цвет кожи человека сильно различается среди человеческих рас. Из-за вышеперечисленных проблем, в современных подходах, цвет кожи рассматривается только как один из многих параметров при идентификации жестов.
-
Локальные признаки
В распознавании жестов на основе изображения условия освещения сильно влияют на качество идентификации жестов. Поэтому многие исследователи используют метод локальных признаков, который не чувствителен к условиям освещения. Локальный подход к объектам – это детализированный подход на основе текстур. Он раскладывает изображение на более мелкие области, которые не соответствуют частям тела [40]. Как показано на Рис. 4, одной из наиболее важных локальных функций является преобразование признаков инвариантных объектов (SIFT) [41]. Метод SIFT является вращательным, трансляционным, масштабируемым и частично осветляющим инвариантом. Существует несколько подобных методов локальных признаков, например, SURF и ORBare, предложенные в более поздние годы [42, 43]. Как правило, подходы к локальным особенностям также рассматриваются только как один из множества параметров при идентификации жестов. Несколько методов идентификации, таких как методы формы и контура, методы движения и методы обучения, основаны на локальных признаках.
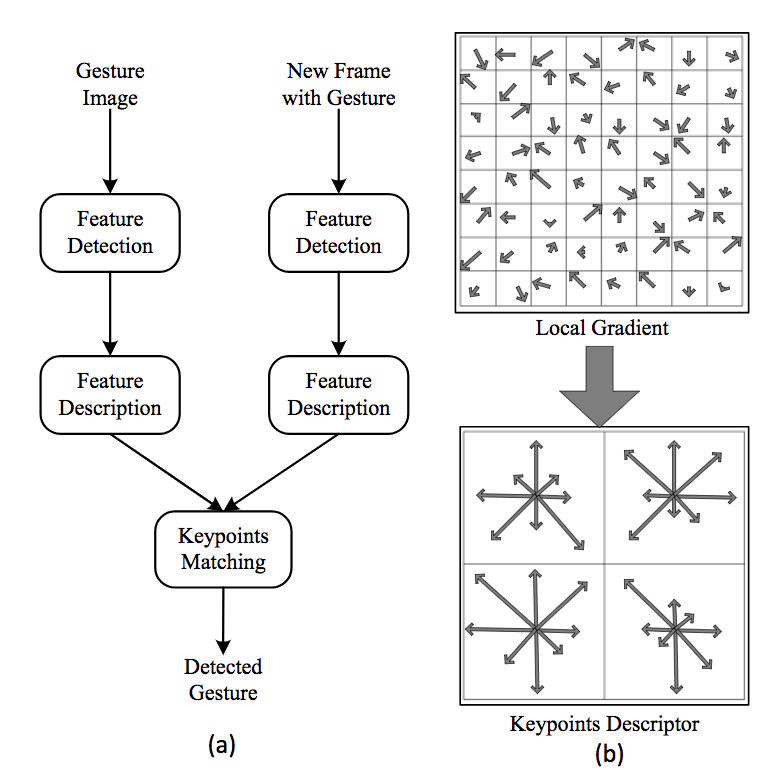
Рис. 4. SIFT: (a) алгоритм SIFT для идентификации жестов; (b) Пример дескриптора функции SIFT [41].
-
Форма и контур
Другой интуитивный и простой способ идентификации жестов - использование уникальной форму и контура человеческого тела в среде HRC. Существенный вклад в определение формы и соответствия был внесен Belongie (соавторство) [44]. Они ввели метод дескриптора контекста формы. Дескриптор контекста формы используется для обнаружения похожих фигур на разных изображениях. Разработка датчика глубины дает возможность точно измерять форму поверхности. 3D-модели, созданные на основе технологий, позволяют очень детально представлять форму человеческого тела [45].
-
Движение
В конкретной среде HRC человек является единственным движущимся объектом в массиве необработанных данных. Поэтому движение является полезной функцией для обнаружения человеческих жестов. Оптический поток является ключевой технологией идентификации жестов на основе движения. Оптический поток не нуждается в вычитании фона, что является преимуществом по сравнению с подходами на основе формы и контура. Несколько приложений распознавания жестов реализованы на основе метода оптического потока [46, 47]. Далал и Турау [48] представили знаменитый метод гистограмм ориентированных градиентов (HOG). Дескрипторы HOG делят кадры изображения на блоки. Для каждого блока вычисляется гистограмма. Среди подходов, основанных не на изображении, распознавание жестов на основе движения является популярным методом [37, 49]. Пороговые значения и фильтрация обычно применяются к необработанным данным с датчика для идентификации человеческих жестов.
3.2. Алгоритмы обучения
Недавняя тенденция идентификации жестов заключается в применении алгоритмов обучения, особенно для обнаружения статических жестов, которые могут быть представлены в одном кадре. Методы визуальной функции основаны на различных визуальных особенностях, в то время как алгоритмы обучения используют алгоритмы машинного обучения для определения жестов из необработанных данных датчика. Хотя некоторые алгоритмы основаны на методах визуальных признаков, удаление фона изображения не всегда необходимо для корректной работы алгоритмов. В системах распознавания жестов широко применяются алгоритмы обучения, такие как метод опорных векторов (SVM), искусственные нейронные сети (ANN) и случайные решения (RDF) [50-52].
3.3. Модель человека
В отличие от вышеупомянутых подходов, модельный подход использует явную модель человеческого тела для восстановления позы человеческого тела. Поэтому модельный подход также называется генеративным подходом. Поскольку идентификация жестов на основе модели человеческого тела дает преимущество упрощения процесса классификации жестов, подход с использованием модели человека стал популярным решением при работе с датчиками глубины [53]. Современные исследования идентификации жестов на основе модели человека можно разделить на два типа: идентификация модели рук и идентификация модели скелета тела.
-
Модель руки
Существует три основных подхода к моделированию ручных моделей: модель формы, трехмерная модель и модель ручного скелета. Подход, основанный на форме, соответствует предварительно построенной формы руки из наблюдений [54]. Подход 3D-модели интерпретирует проблему обнаружения руки как проблему оптимизации, которая минимизирует различия между моделью 3D-руки и наблюдаемой рукой [55]. Подход модели с ручным скелетом похож на подход трехмерного моделирования [27].
-
Модель телесного скелета
Чтобы определить жест тела, подробная человеческая модель бесполезна. Однако, в задаче идентификации жестов тела, модель самого скелета тела является популярным подходом. Большая часть литературы по алгоритмам для обработки скелета тела основана на информации о глубине, собранной с датчиков глубины. Как показано на Рис. 5, модель скелета тела представляет собой упрощенную модель человеческого тела, которая сохраняет информацию о суставах тела.
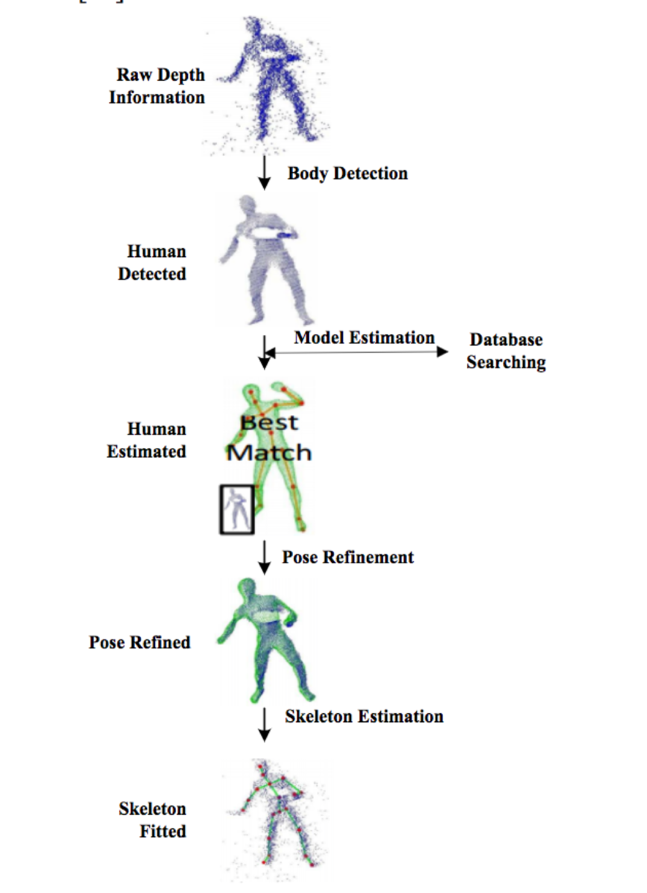
Рис. 5. Пример идентификации скелета тела [58]
Ввиду того, что только самая полезная информация извлекается из модели человеческого тела, в исследованиях распознавания жестов тела методы скелета тела применяются все чаще [53, 56, 57].
3.4. Резюме по подходам идентификации жестов
Таблица 2 представляет наиболее подходящие способы идентификации жестов для каждого популярного датчика. Из-за характера HRC, работники-люди являются наиболее важными членами команды HRC. Несмотря на понимание жестов человеческого тела, подход моделирования человеческого тела также будет контролировать человеческие движения, что обеспечивает безопасную среду для совместной работы роботов и людей. Как упоминалось ранее, модель скелета тела упрощает телесную модель человека, а информация о суставах тела легко извлекается. Более того, скелетные подходы могут упростить последующий процесс классификации жестов. Поэтому в настоящее время модели с использованием скелетного подхода является подходящим решением для распознавания жестов в системах HRC.
Таблица 2. Методы идентификации жестов для разных датчиков.
|
Датчик |
Метод идентификации жестов |
|
Системы с одной камерой |
В системах с одной камерой могут быть реализованы методы визуальных признаков и алгоритмы обучения. Для обеспечения надежной работы следует применять алгоритмы обучения. Чтобы добиться более быстрой обработки изображений, следует применять метод визуальных признаков [13]. |
|
Датчик глубины |
Поскольку метод человеческой модели использует и упрощает информацию из облака точек, метод человеческой модели является лучшим вариантом для систем с датчиками глубины [53]. |
|
Браслет (сенсоры на базе браслета) |
Никакие визуальные методы не могут применяться для систем на базе браслетов. Обычно собранные данные требуют базовой фильтрации для идентификации жестов, а алгоритмы обучения будут реализованы на более поздней стадии классификации жестов [31, 59]. |
|
Бесконтактные датчики |
Бесконтактные датчики также принимают данные сигналов вместо изображений. Из-за того, что радиочастотные сигналы содержат шумы [37, 38], современные системы фильтрации и обработки должны быть реализованы в бесконтактных системах. |
4. Отслеживание жестов
При распознавании жестов понятие отслеживания используется по-разному в разных литературе. Мы определяем понятие отслеживания как процесс поиска временных соответствий между кадрами. В частности, мы фокусируемся на проблеме отслеживания жестов, которая связывает идентифицированный жест в предыдущих кадрах с текущим фреймом. Что касается статических жестов, которые могут быть представлены одним кадром, отслеживание жестов не требуется. Пример отслеживания жестов показан на Рис. 6.
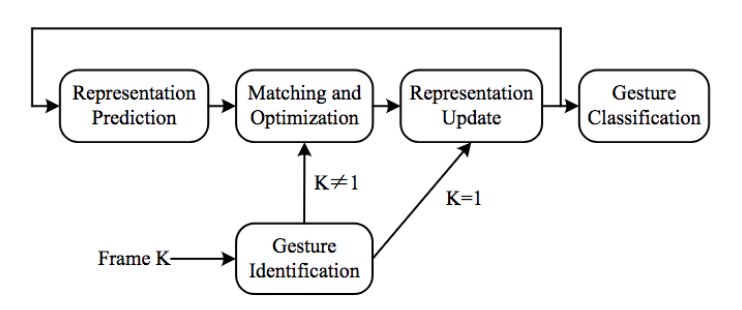
Рис. 6. Пример отслеживания жестов
4.1. Отслеживание единичной гипотезы
Отслеживание единичной гипотезы относится к оценке наилучшего соответствия при согласовании с минимальной ошибкой. Поэтому при использовании единичной гипотезы отслеживания, жест представлен только одной гипотезой. Большинство усовершенствованных алгоритмов отслеживания основаны на технологиях единичной гипотезы.
-
Средний сдвиг
Отслеживание методом среднего сдвига – это базовая технология отслеживания. Метод выполняет сопоставление с гистограммами цвета RGB [60]. Для каждого нового кадра средний сдвигающий трекер сравнивает расстояние Бхаттачарьи между гистограммами целевого окна нового кадра и кадрами старого кадра. Полное математическое объяснение можно найти в [60].
-
Фильтр Калмана
Фильтр Калмана (KF) представляет собой рекурсивный алгоритм реального времени, используемый для оптимальной оценки лежащих в основе состояний ряда шумовых и неточных результатов измерений, наблюдаемых с течением времени. Технологический поток KF показан на Рис. 7. Полный математический вывод KF можно найти в [61, 62]. В настоящее время KF активно развивается и применяется в различных областях, таких как аэрокосмическая промышленность, робототехника и экономика.
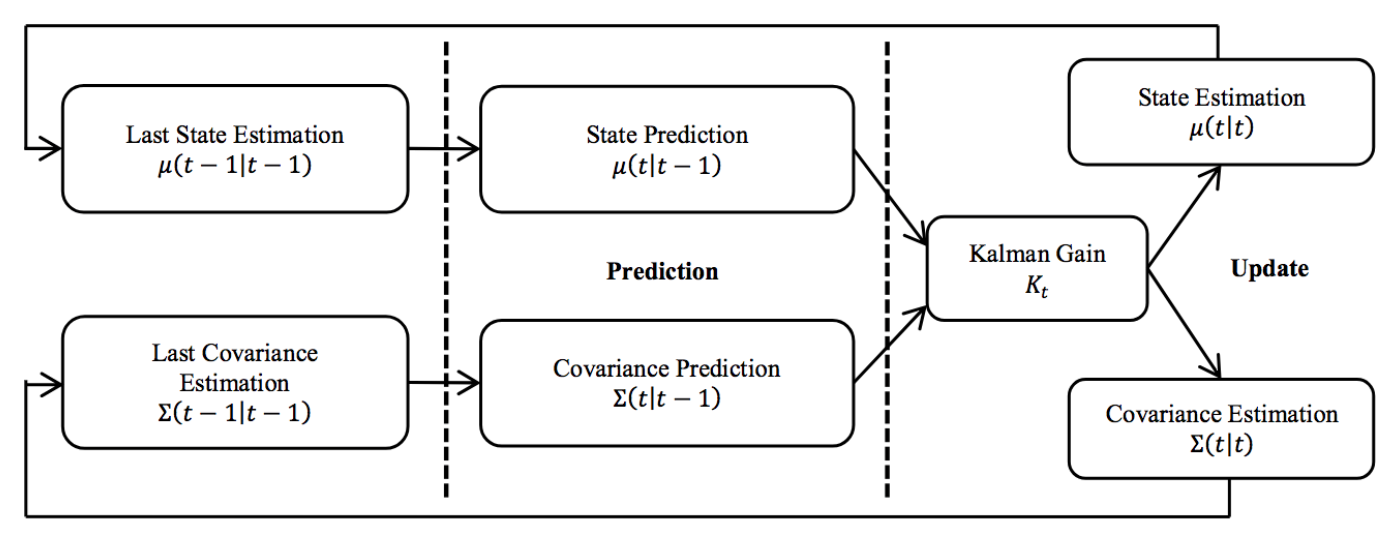
Рис. 7. Процесс работы фильтра Калмана [69].
-
Расширеные фильтры Калмана
KF предполагает, что вектор состояния является линейной моделью. Расширеный фильтр Калмана (Extend Kalman Filter – EKF) является функциональным алгоритмом отслеживания, даже если модель нелинейна [63]. Другим алгоритмом, который решает ту же проблему под другим углом, является сигма-точечный фильтр Калмана (Unscented Kalman Filter – UKF) [64]. UKF решает проблему, применяя детерминированный подход с взвешенной выборкой. Распределение состояний представлено с использованием минимального набора выбранных точек выборки.
4.2. Отслеживание множественных гипотез
Во многих сценариях HRC одновременно работают несколько рабочих-людей на одной рабочей станции [1]. Чтобы отслеживать жесты нескольких работников одновременно, следует применять технологии отслеживания множественных гипотез.
-
Многочастичный фильтр
Многочастичный фильтр (Фильтр частиц, Particle Filter – PF) является популярной технологией в задачах робототехники. В отличие от KF, PF не делает предположения о поздней модели. Представление PF является непараметрическим приближением, которое может представлять собой более широкое пространство распределения. Следовательно, PF удовлетворяет требованиям по отслеживанию гипотез [65]. Пример PF показан на Рис. 8. Несколько расширенных алгоритмов отслеживания также применяют PF для сканирования функции плотности вероятности [66-68].
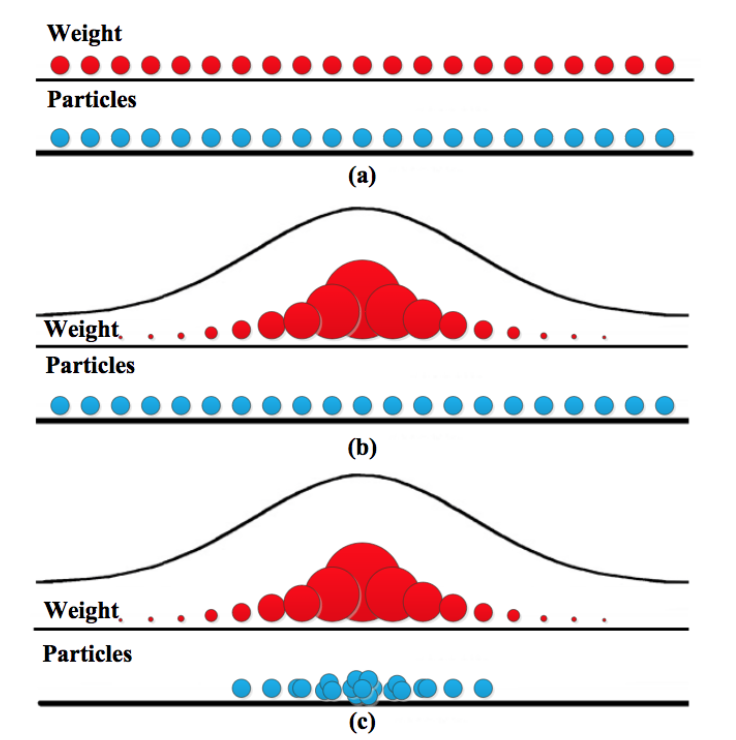
Рис. 8. Частицы и весовые коэффициенты: (а) после инициализации частиц; (b) после расчета весового коэффициента; © после повторной дискретизации [69]
-
Расширения многочастичного фильтра
Многие исследователи пытались объединить PF с другими алгоритмами. Исследователи объединили PF со средним сдвиговым трекером, генетическим алгоритмом, PSO, Ant Colony Optimization и другими алгоритмами машинного обучения для решения проблемы вырождения и истощения выборки [70]. Некоторые другие исследователи также улучшили стратегию передискретизации PF [71, 72].
4.3. Расширенные методы отслеживания
За последнее время появилось много продвинутых методов отслеживания. Некоторые из этих передовых методов использовали часть алгоритмов отслеживания, упомянутых выше. Другие методы улучшили отслеживаемость с помощью алгоритмов обнаружения или обучения.
-
Расширенное отслеживание модели
Для долгосрочных проблем отслеживания многие алгоритмы отслеживания терпят неудачу, поскольку цель поддерживает фиксированные модели. Расширенное отслеживание модели сохраняет целевое поведение или внешний вид из последних кадров изображения. Поэтому для целевой оценки зарезервировано больше целевой информации. Инкрементный визуальный трекер использует расширенную модель для сохранения большего объема информации для процесса отслеживания [73]. Квон [67] представил Отслеживание с помощью выборочного отслеживания. Расширенная модель сохраняется в процессе выборки. Трекер выбирает из многих трекеров и, соответственно, выбирается наиболее подходящий трекер.
-
Отслеживание путем обнаружения
Еще один вид алгоритмов отслеживания строится на базе алгоритмов обучения идентификации жестов. Для этих алгоритмов отслеживания в кадрах изображений применяется классификатор или детектор, чтобы идентифицировать жест из справочной информации [68]. Одним из характерных подходов является трекер отслеживания, обучения и обнаружения [74]. Этот подход объединяет результаты детектора объекта с устройством оптического отслеживания потока. Еще одна типичная технология отслеживания по обнаружению – применять множественное обучение экземпляров [75]. Алгоритм обучения может повысить надежность трекера и уменьшить количество параметров.
4.4. Сравнение различных подходов отслеживания жестов
Смеулдерз [76] представил результат теста различных алгоритмов отслеживания жестов. Итоговый результат - нормализованный F-балл. F-балл дает нам представление о среднем охвате ограничивающего блока отслеживаемого объекта и ограничительной рамки истины. Поэтому, чем выше F-оценка, тем лучше качество отслеживания. На Рис. 9 представлены результаты испытаний в разных условиях видео.
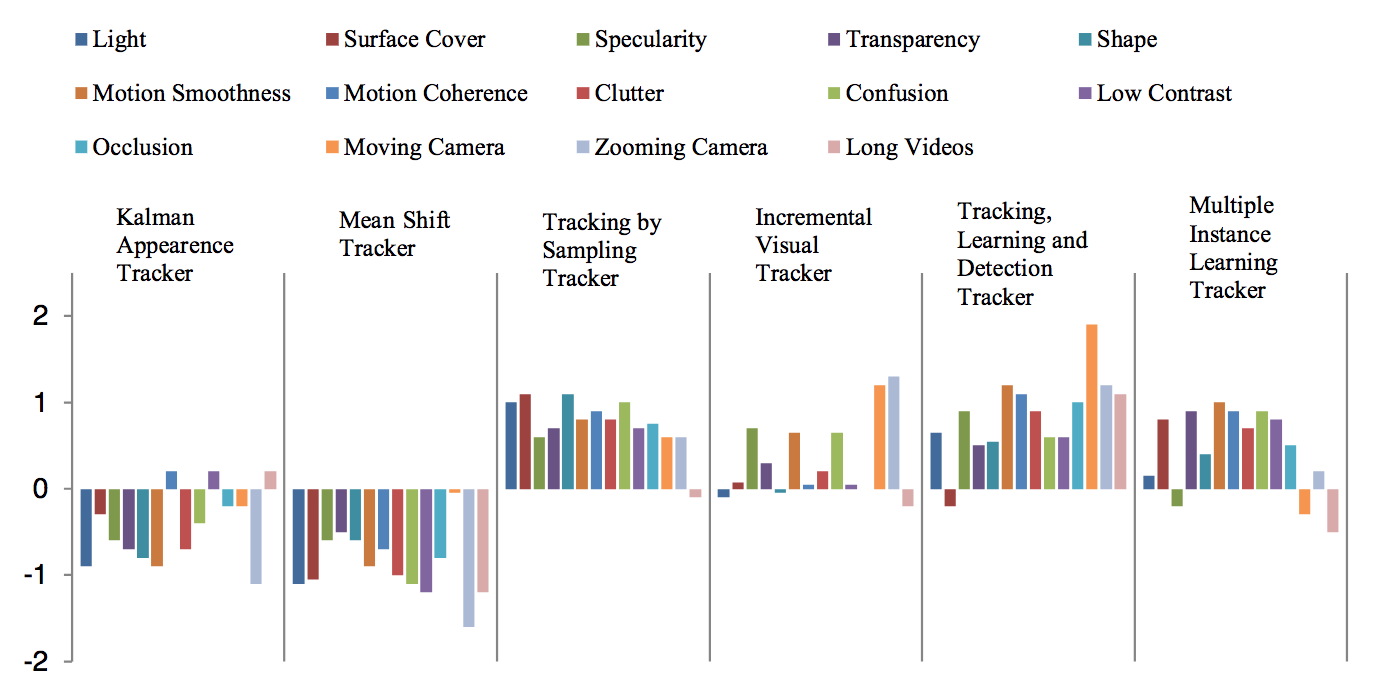
Рис. 9. Результат теста алгоритмов отслеживания в разных видео условиях [76]
Kalman Appearance Tracker (трекер появления Калмана) и Mean Shift Tracker (трекер среднего сдвига) относятся к трекеру единичной гипотезы. Отслеживание с помощью Sampling Tacker (трекер отбора) и Incremental Visual Tracker (инкрементный визуальный трекер) относится к расширенной модели отслеживания. Трекеры отслеживания и трекеры обнаружения нескольких экземпляров относятся к методу обнаружения. Легко заметить, что трекеры одиночной гипотезы менее производительны, чем остальные. Таблица 3 содержит резюме различных подходов к отслеживанию жестов.
Таблица 3. Обзор подходов к отслеживанию.
|
Подход |
Описание |
|
Единичная гипотеза |
Быстрый и простой алгоритм. Подходит для отслеживания одного жеста в контролируемой среде. |
|
Множественные гипотезы |
Возможность отслеживания нескольких целей одновременно. Подходит для отслеживания нескольких жестов в контролируемой среде. |
|
Расширенная модель трекинга |
Целевая история сохраняется и доступна для целевой оценки. Подходит для долговременного отслеживания жестов. |
|
Отслеживание путем обнаружения |
Алгоритм обучения повышает надежность и снижает уровень шума. Этот комбинированный подход имеет предпочтительную производительность в тестах. Подходит для отслеживания жестов в сложной среде. |
5. Классификация жестов
Классификация жестов – это последний и самый важный шаг в распознавании жестов. Большинство человеческих жестов – это динамические жесты. Один динамический жест всегда состоит из нескольких кадров. Чтобы классифицировать динамические жесты, классификация жестов должна выполняться после или вместе с отслеживанием жестов.
5.1. Метод K-ближайших соседей (K-Nearest Neighbours)
Алгоритм K-Nearest Neighbors (KNN) – это фундаментальный и базовый алгоритм классификации жестов, который классифицирует входные данные в соответствии с ближайшими примерами обучения [77]. Применение KNN в классификации жестов можно найти в [77].
5.2. Скрытая Марковская модель
Скрытая Марковская модель (HMM) – популярный алгоритм классификации жестов. HMM – это комбинация ненаблюдаемой цепи Маркова и стохастического процесса. Пример HMM показан на Рис. 10, ненаблюдаемая цепь Маркова состоит из состояний X и вероятностей перехода состояний a. Стохастический процесс состоит из возможных наблюдений O и возможных выводов b. Распознавание жеста – это проблема, которая задает последовательность наблюдений O, идентифицирует наиболее вероятную последовательность состояний X [78, 79]. Для решения проблемы применяется алгоритм максимизации ожидания (EM) [79]. Существует много работ, посвященных приложениям распознавания жестов HMM [80-82]. В некоторых документах объединены HMM с другими подходами к классификации [81], в других – расширения алгоритма HMM в более широкий спектр приложений [82].
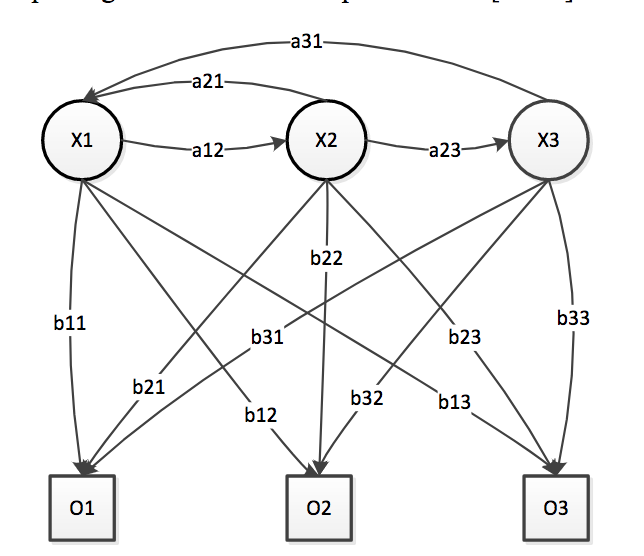
Рис. 10. Пример скрытой Марковской модели [83].
5.3. Метод опорных векторов (Support Vector Machine)
Как показано на Рис. 11, метод опорных векторов (SVM) является дискриминационным классификатором, определяемым разделительной гиперплоскостью [84, 85]. Границы решения классификации определяются путем максимизации расстояния от границы. Оптимальная разделительная гиперплоскость максимизирует запас обучающих данных. Примеры обучения, наиболее близкие к оптимальной гиперплоскости, называются вспомогательными векторами.
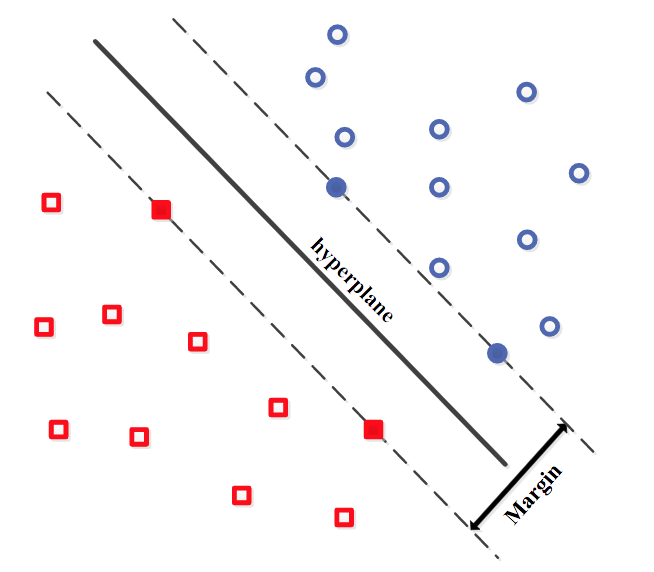
Рис. 11. Пример линейного метода опорных векторов [84, 85].
Общей проблемой для SVM является то, что число векторов поддержки растет линейно с размером обучающего набора. Некоторые исследователи предложили релевантный метод опорных векторов (RVM) для решения проблемы [86]. Трюк ядра (kernel trick) SVM [88] был введен Шолькопфом [87]. Также имеется много работ, которые объединяли SVM с другими методами классификации для улучшения показателей классификации жестов [89-91].
5.4. Метод ансамбля
Метод ансамбля – это еще один широко используемый алгоритм классификации жестов. Основное предположение ансамблевого метода состоит в том, что ансамбли более точны, чем слабые отдельные классификаторы. Одним из известных методов ансамбля является бустинг [92, 93]. Алгоритм бустинга начинается с нескольких слабых классификаторов. Слабые классификаторы применяются многократно. В обучающей итерации часть обучающих образцов используется в качестве входных данных. После итерации обучения создается новая граница классификации. После всех итераций алгоритм бустинга объединяет эти границы и сливается в одну конечную границу предсказания. Как показано на Рис. 12, другим известным ансамблевым методом является алгоритм Адабуст (Adaboost). Существенным преимуществом алгоритма Адабуст является то, что Адабуст не нуждается в большом количестве обучающих данных. В нескольких статьях применялся алгоритм Adaboost в распознавании и классификации жестов [94, 95].
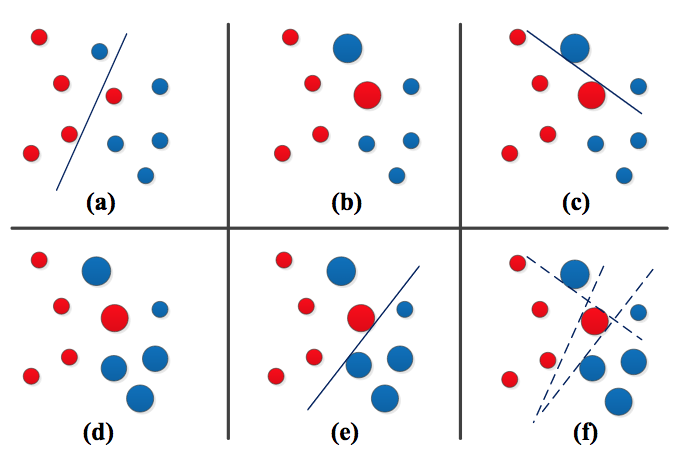
Рис. 12. Пример Адабуст: (a) слабый классификатор 1, (b) увеличение веса, © слабый классификатор 2, (d) увеличение веса, (e) слабый классификатор 3, (f) граница окончательного решения [93].
5.5. Динамическое деформирование временных рядов
Динамическое деформирование временных рядов (DTW) является оптимальным алгоритмом выравнивания для двух последовательностей. DTW генерирует кумулятивную матрицу расстояний, которая искажает последовательности нелинейным способом. Первоначально DTW использовался для распознавания речи. В последнее время существует множество приложений DTW в распознавании жестов [96, 97]. В некоторых статьях также вводилось деривативное динамическое временное деформирование (DDTW) как расширение DTW [98, 99].
5.6. Искусственные нейронные сети
Искусственная нейронная сеть (ANN) – это семейство моделей обработки информации, основанных на биологических нейронных сетях [100]. ANN состоит из множества взаимосвязанных обрабатывающих объединений (нейронов), которые работают параллельно. Каждый союз (нейрон) получает входные данные, обрабатывает входные данные и дает выходные данные. ANN может использоваться для оценки функций, зависящих от большого количества входных данных. В последнее время существует много исследований, в которых используются ANN для распознавания жестов [101-103]. В нескольких статьях также представлена система распознавания жестов, в которой объединены ANN с другими методами классификации [104-106].
5.7. Глубокое обучение (Deep Learning)
Глубокое обучение – это быстро развивающаяся отрасль машинного обучения. Глубокое обучение позволяет компьютеру моделировать данные с абстракциями высокого уровня, используя множественную нейронную сеть на уровне обработки. Более того, в отличие от традиционных алгоритмов обучения, глубокое обучение не требует ручной подготовки данных, что позволяет использовать преимущества экспоненциально увеличивающихся объемов доступных данных и вычислительных мощностей [107]. В настоящее время глубокое обучение применяется в распознавании изображений, распознавании речи, анализе данных и т. д. [108]. В частности, глубокое обучение используется для решения проблемы распознавания человеческих действий в режиме реального времени в режиме видеомониторинга, в котором содержится большое количество данных [109, 110]. В настоящее время наиболее популярны две революционные нейронной сети: сверточные (CNN) и рекуррентные (RNN) для глубоких обучающих архитектур [107]. В последнее время несколько систем распознавания жестов используют алгоритмы глубокого обучения [111, 112].
5.8. Сравнение подходов классификации жестов
Таблица 4 содержит преимущества и недостатки подходов к классификации жестов.
Таблица 4. Преимущества и недостатки подходов к классификации жестов.
|
Подход |
Преимущества |
Недостатки |
|
Метод K-ближайших соседей |
Простота |
K-параметр следует выбирать осторожно |
|
Скрытая Марковская модель |
Гибкость обучения и проверки, прозрачность модели [113] |
Необходимо отрегулировать множество свободных параметров [113] |
|
Метод опорных векторов |
Могут применяться различные функции ядра [87] |
Число опорных векторов растет линейно с размером обучающего набора [86] |
|
Метод ансамбля |
Не требуется большого количества данных обучения |
Легко переобучить, чувствительность к шумам и выбросам (outliers) |
|
Динамическое деформирование временных рядов |
Надежное нелинейное выравнивание между образцами [114] |
Сложность времени и по объему данных [115] |
|
Искусственные нейронные сети |
Может обнаруживать сложные нелинейные зависимости между переменными [116] |
Принцип «черного ящика», не может использоваться при наличии небольшого набора данных для обучения [116] |
|
Глубокое обучение |
Не нуждаются в хорошей подготовке признаков, превосходит другие методы машинного обучения [107] |
Требуется большое количество обучающих данных и значительные вычислительные мощности. |
Одной из тенденций является подход глубокого обучения. Основными ограничениями глубокого обучения являются ограниченные вычислительные мощности. Однако экспоненциально возрастающая вычислительная мощность может легко решить эту проблему. Количество приложений классификации жестов, основанных на глубоком обучении, быстро растет. Другая тенденция заключается в объединении различных алгоритмов классификации. Каждый алгоритм классификации имеет свои преимущества и недостатки. Чтобы использовать это, различные классификаторы могут быть объединены для достижения лучшей производительности. Мы также заметили, что важно координировать алгоритмы классификации жестов с помощью алгоритмов идентификации и трекинга жестов.
6. Статистический анализ
В этом разделе представлен краткий статистический анализ технологий распознавания жестов. Как показано на Рис. 13, мы выбрали 9 различных журналов и конференций, в которых каждый опубликовал более 5 статей в 285 обзорах, связанных с распознаванием жестов. По количеству документов 65% составляют доклады конференций, 35% - журнальные работы. Обратите внимание, что широко распространённая практика в области информатики широко публикуется в материалах конференций. Самая популярная конференция, в которой опубликованы документы, связанные с распознаванием жестов, - Конференция по компьютерному зрению и распознаванию образов.
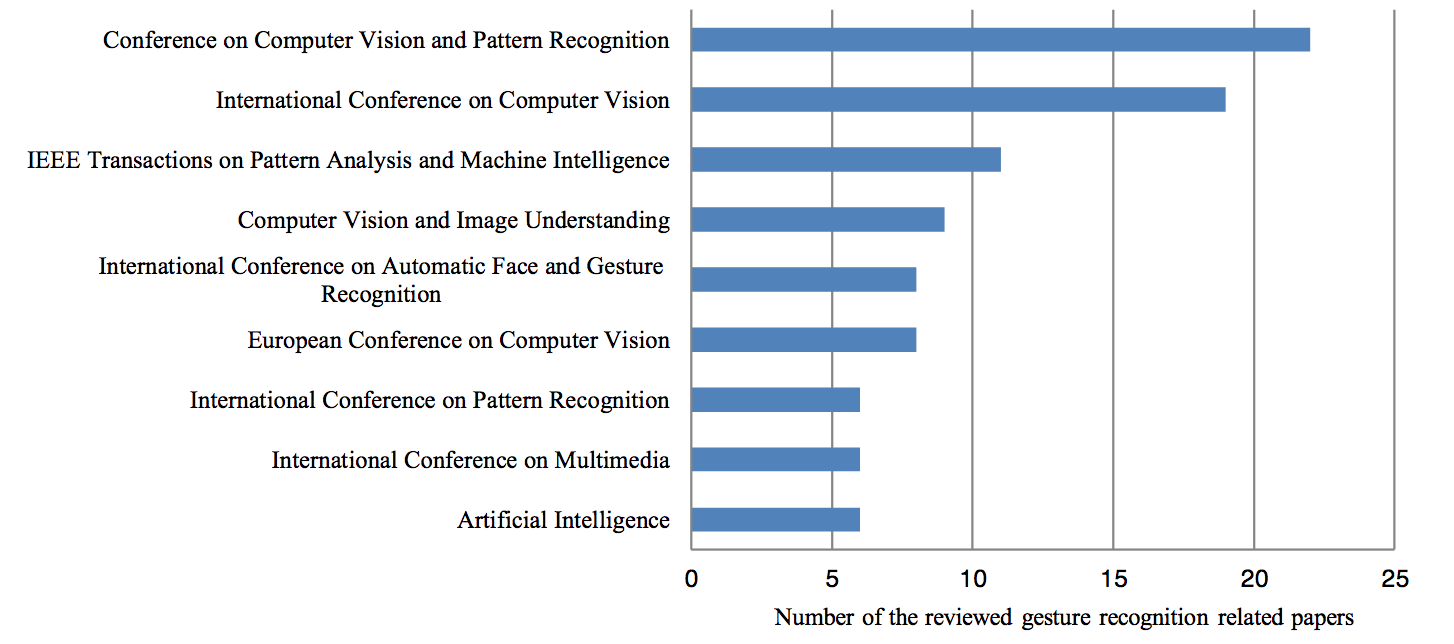
Рис. 13. Журналы и конференции, в которых публикуются наиболее важные документы, связанные с распознаванием жестов
На Рис. 14 показаны годовые распределения рассмотренных документов по распознаванию жестов. Видно, что с 1994 года количество документов по теме распознавания жестов значительно увеличилось, что свидетельствует о растущих интересах в этой области.
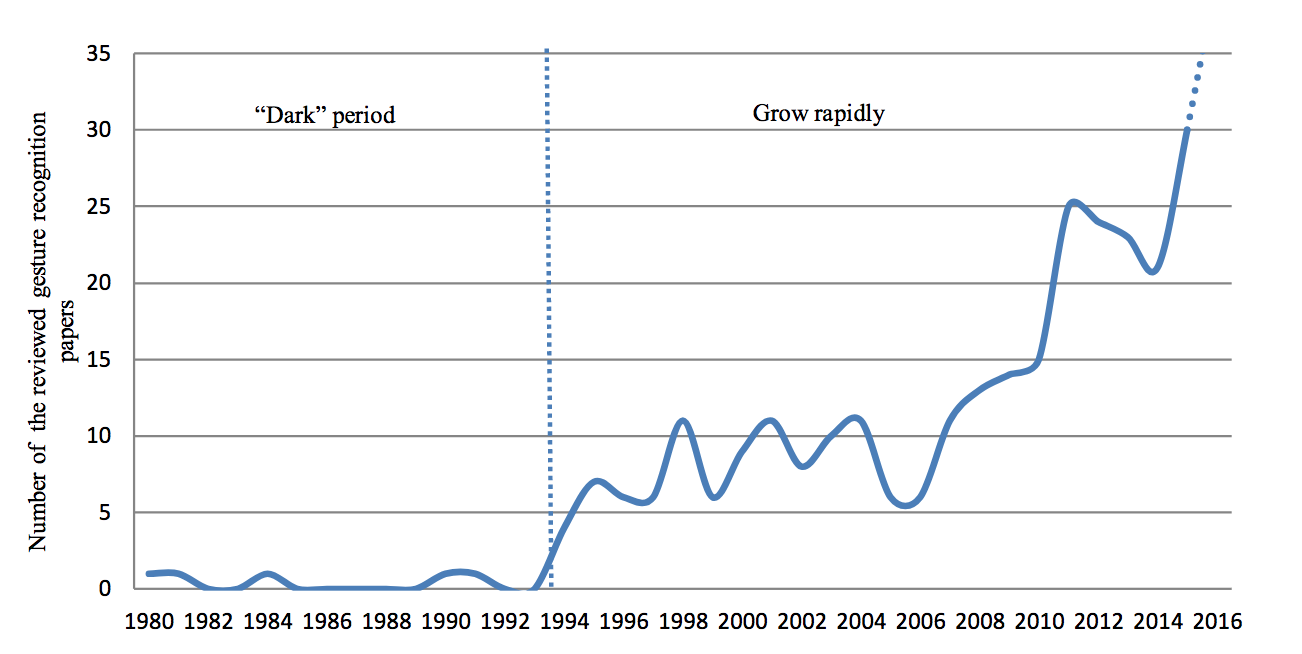
Рис. 14. Ежегодные распределения рассмотренных документов, связанных с распознаванием жестов.
На Рис. 15 показана годовая тенденция развития четырех технических компонентов в области распознавания жестов.
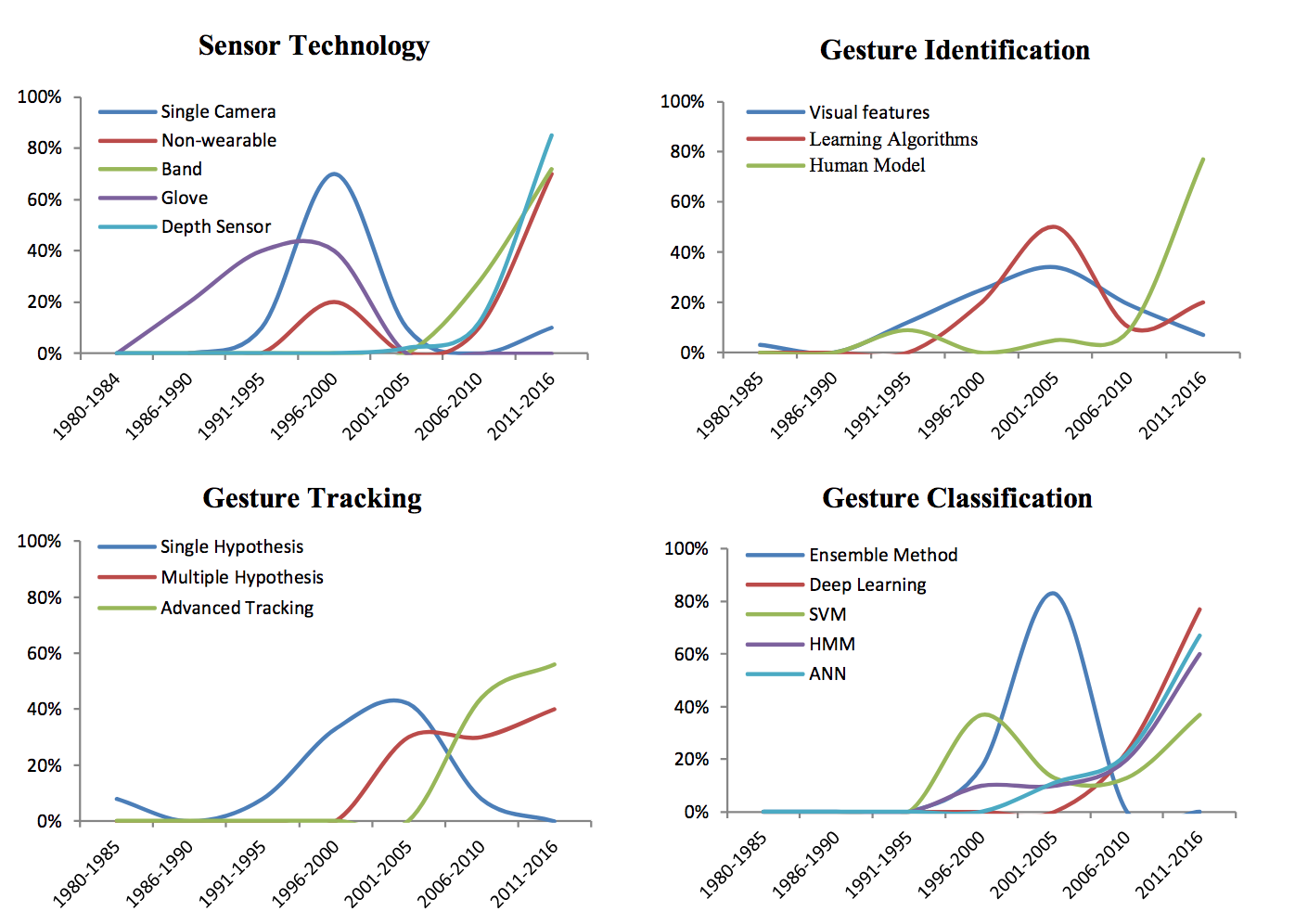
Рис. 15. Статистический анализ документов в четырех технических компонентах распознавания жестов.
Горизонтальная ось представляет собой процент статей, цитируемых за определенный период времени, по сравнению со всеми документами, рассмотренными по этой технологии. Стоит заметить, что:
-
Датчик глубины – это быстро развивающаяся технология среди сенсорных технологий. Также быстро развиваются носимые и бесконтактные сенсоры.
-
Метод человеческого моделирования является наиболее перспективной технологией среди подходов к идентификации жестов.
-
Расширенные методы отслеживания появляются наравне с другими методами отслеживания жестов.
-
Глубокое обучение и ANN быстро растут среди технологий классификации жестов. В последнее время часто используются и другие технологии, такие как скрытая Марковская модель и метод опорных векторов.
Статистический анализ подтвердил наши результаты технического анализа в предыдущих разделах.
7. Выводы и будущие тенденции
Хотя приведенные выше разделы предоставляют общую картину проблемы распознавания жестов для HRC, нелегко обобщить такую междисциплинарную и быстро развивающуюся область. Технологии, связанные с сенсорами, обычно начинаются с аппаратного обеспечения. Программные технологии и алгоритмы предназначены для использования производительности оборудования. Поэтому мы представим некоторые из прогнозируемых будущих тенденций, начиная с сенсорных технологий.
-
Датчик глубины и распознавание жестов на основе модели человека.
Из-за характера HRC люди являются наиболее важными членами любой команды HRC. Несмотря на понимание жестов человеческого тела, датчик глубины вместе с подходом к модели тела контролирует движение человека, что обеспечивает более безопасную среду для HRC. Более того, модель скелета тела упростит процесс классификации жестов. Поэтому может применяться более простой метод отслеживания жестов и классификации.
-
Бесконтактный датчик и распознавание жестов на основе глубокого обучения.
Хотя бесконтактные технологии еще не совсем готовы, они по-прежнему являются самыми перспективными датчиками, не на базе изображений. В HRC люди должны иметь возможность общаться с роботами естественным образом. Для этой цели ничто не должно быть привязано к телу. Бесконтактные датчики по-прежнему страдают низким качеством идентификации жестов и качеством классификации. Проблема может быть решена с помощью методов глубокого обучения.
-
Надежная система распознавания жестов в реальном времени.
Одним из важнейших требований в отрасли является требование работы в реальном времени. Особенно, в системе HRC безопасность персонала всегда является первоочередной задачей. Таким образом, система распознавания жестов в реальном времени является еще одним будущим направлением. В настоящее время датчики диапазона и перчаток обеспечивают самый быстрый ответ. Кроме того, недавно появилась высокоскоростная система распознавания жестов с помощью одной камеры [13]. В идентификации жестов, отслеживании и классификации должны применяться самые быстрые и эффективные методы.
-
Система распознавания жестов с несколькими датчиками
Все датчики имеют преимущества и недостатки. Например, датчик-браслет имеет большую зону зондирования; Kinect обладает хорошими характеристиками в распознавании жестов тела. Чтобы наилучшим образом использовать потенциал производительности системы, в одной и той же системе могут комбинироваться различные датчики распознавания жестов.
-
Комбинационный алгоритмический подход
Аналогично датчикам, разные алгоритмы классификации жестов также имеют свои преимущества и недостатки. Как мы упоминали в разделе классификации жестов, комбинация алгоритмов повышает эффективность.
Список литературы
[1] J. Krüger, T. Lien, A. Verl, Cooperation of human and machines in assembly lines, CIRP Annals-Manufacturing Technology, 58 (2009) 628-646.
[2] S.A. Green, M. Billinghurst, X. Chen, G. Chase, Human-robot collaboration: A literature view and augmented reality approach in design, International Journal of Advanced Robotic Systems, (2008) 1-18.
[3] P.R. Cohen, H.J. Levesque, Teamwork, Nous, (1991) 487-512.
[4] L.S. Vygotsky, Mind in society: The development of higher psychological processes, Harvard university press, 1980.
[5] P.R. Cohen, H.J. Levesque, Persistence, intention, and commitment, Reasoning about actions and plans, (1990) 297-340.
[6] C. Breazeal, A. Brooks, J. Gray, G. Hoffman, C. Kidd, H. Lee, J. Lieberman, A. Lockerd, D. Mulanda, Humanoid robots as cooperative partners for people, Int. Journal of Humanoid Robots, 1 (2004) 1-34.
[7] A. Bauer, D. Wollherr, M. Buss, Human–robot collaboration: a survey, International Journal of Humanoid Robotics, 5 (2008) 47-66.
[8] S. Mitra, T. Acharya, Gesture recognition: A survey, Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 37 (2007) 311-324.
[9] R. Parasuraman, T.B. Sheridan, C.D. Wickens, A model for types and levels of human interaction with automation, Systems, Man and Cybernetics, Part A: Systems and Humans, IEEE Transactions on, 30 (2000) 286-297.
[10] T.E. Starner, Visual Recognition of American Sign Language Using Hidden Markov Models, (1995).
[11] T. Starner, J. Weaver, A. Pentland, Real-time American sign language recognition using desk and wearable computer based video, in: Pattern Analysis and Machine Intelligence, IEEE Transactions on, 1998, pp. 1371-1375.
[12] N.R. Howe, M.E. Leventon, W.T. Freeman, Bayesian Reconstruction of 3D Human Motion from Single-Camera Video, in: NIPS, 1999, pp. 820-826.
[13] Y. Katsuki, Y. Yamakawa, M. Ishikawa, High-speed Human/Robot Hand Interaction System, in: Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction Extended Abstracts, ACM, 2015, pp. 117-118.
[14] M. Elmezain, A. Al-Hamadi, J. Appenrodt, B. Michaelis, A hidden markov model-based continuous gesture recognition system for hand motion trajectory, in: Pattern Recognition, 2008. ICPR 2008. 19th International Conference on, IEEE, 2008, pp. 1-4.
[15] Y. Matsumoto, A. Zelinsky, an algorithm for real-time stereo vision implementation of head pose and gaze direction measurement, in: Automatic Face and Gesture Recognition, 2000. Proceedings. Fourth IEEE International Conference on, IEEE, 2000, pp. 499-504.
[16] J.P. Wachs, M. Kölsch, H. Stern, Y. Edan, Vision-based hand-gesture applications, Communications of the ACM, 54 (2011) 60-71.
[17] J. Suarez, R.R. Murphy, Hand gesture recognition with depth images: A review, in: RO-MAN, 2012 IEEE, IEEE, 2012, pp. 411-417.
[18] P. Doliotis, A. Stefan, C. McMurrough, D. Eckhard, V. Athitsos, comparing gesture recognition accuracy using colorand depth information, in: Proceedings of the 4th international conference on Pervasive technologies related to assistive environments, ACM, 2011, pp. 20.
[19] M. Hansard, S. Lee, O. Choi, R.P. Horaud, Time-of-flight cameras: principles, methods and applications, Springer Science & Business Media, 2012.
[20] T. Kapuściński, M. Oszust, M. Wysocki, Hand gesture recognition using time-of-flight camera and viewpoint feature histogram, in: Intelligent Systems in Technical and Medical Diagnostics, Springer, 2014, pp. 403-414.
[21] S.B. Gokturk, H. Yalcin, C. Bamji, A time-of-flight depth sensor-system description, issues and solutions, in: Computer Vision and Pattern Recognition Workshop, 2004. CVPRW'04. Conference on, IEEE, 2004, pp. 35-35.
[22] J.D. Arango Paredes, B. Munoz, W. Agredo, Y. Ariza-Araujo, J.L. Orozco, A. Navarro, A reliability assessment software using Kinect to complement the clinical evaluation of Parkinson's disease, in: Engineering in Medicine and Biology Society (EMBC), 2015 37th Annual International Conference of the IEEE, IEEE, 2015, pp. 6860-6863.
[23] F. Anderson, T. Grossman, J. Matejka, G. Fitzmaurice, YouMove: enhancing movement training with an augmented reality mirror, in: Proceedings of the 26th annual ACM symposium on User interface software and technology, ACM, 2013, pp. 311-320.
[24] S. Obdrzalek, G. Kurillo, F. Ofli, R. Bajcsy, E. Seto, H. Jimison, M. Pavel, Accuracy and robustness of Kinect pose estimation in the context of coaching of elderly population, in: Engineering in medicine and biology society (EMBC), 2012 annual international conference of the IEEE, IEEE, 2012, pp. 1188-1193.
[25] C. Wang, Z. Liu, S.-C. Chan, Superpixel-Based Hand Gesture Recognition with Kinect Depth Camera, Multimedia, IEEE Transactions on, 17 (2015) 29-39.
[26] A. Kurakin, Z. Zhang, Z. Liu, A real time system for dynamic hand gesture recognition with a depth sensor, in: Signal Processing Conference (EUSIPCO), 2012 Proceedings of the 20th European, IEEE, 2012, pp. 1975-1979.
[27] J. Shotton, T. Sharp, A. Kipman, A. Fitzgibbon, M. Finocchio, A. Blake, M. Cook, R. Moore, Real-time human pose recognition in parts from single depth images, Communications of the ACM, 56 (2013) 116-124.
[28] T. Sharp, C. Keskin, D. Robertson, J. Taylor, J. Shotton, D.K.C.R.I. Leichter, A.V.Y. Wei, D.F.P.K.E. Krupka, A. Fitzgibbon, S. Izadi, Accurate, Robust, and Flexible Real-time Hand Tracking, in: Proc. CHI, 2015.
[29] A. Erol, G. Bebis, M. Nicolescu, R.D. Boyle, X. Twombly, Vision-based hand pose estimation: A review, Computer Vision and Image Understanding, 108 (2007) 52-73.
[30] T. Labs, Myo, in, 2015, pp. https://www.myo.com/.
[31] Y. Zhang, C. Harrison, Tomo: Wearable, Low-Cost Electrical Impedance Tomography for Hand Gesture Recognition, in: Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, ACM, 2015, pp. 167-173.
[32] N. Haroon, A.N. Malik, Multiple Hand Gesture Recognition using Surface EMG Signals, Journal of Biomedical Engineering and Medical Imaging, 3 (2016) 1.
[33] S. Roy, S. Ghosh, A. Barat, M. Chattopadhyay, D. Chowdhury, Real-time Implementation of Electromyography for Hand Gesture Detection Using Micro Accelerometer, in: Artificial Intelligence and Evolutionary Computations in Engineering Systems, Springer, 2016, pp. 357-364.
[34] Google, Project Soli, in, Google, 2015, pp. https://www.google.com/atap/project-soli/.
[35] J. Smith, T. White, C. Dodge, J. Paradiso, N. Gershenfeld, D. Allport, Electric field sensing for graphical interfaces, Computer Graphics and Applications, IEEE, 18 (1998) 54-60.
[36] F. Adib, C.-Y. Hsu, H. Mao, D. Katabi, F. Durand, Capturing the human figure through a wall, ACM Transactions on Graphics (TOG), 34 (2015) 219.
[37] F. Adib, D. Katabi, See through walls with WiFi, ACM, 2013.
[38] F. Adib, Z. Kabelac, D. Katabi, R.C. Miller, 3d tracking via body radio reflections, in: Usenix NSDI, 2014.
[39] J. Letessier, F. Bérard, Visual tracking of bare fingers for interactive surfaces, in: Proceedings of the 17th annual ACM symposium on User interface software and technology, ACM, 2004, pp. 119-122.
[40] D. Weinland, R. Ronfard, E. Boyer, A survey of vision-based methods for action representation, segmentation and recognition, Computer Vision and Image Understanding, 115 (2011) 224-241.
[41] D.G. Lowe, Object recognition from local scale-invariant features, in: Computer vision, 1999. The proceedings of the seventh IEEE international conference on, Ieee,1999, pp. 1150-1157.
[42] H. Bay, T. Tuytelaars, L. Van Gool, Surf: Speeded up robust features, in: Computer vision–ECCV 2006, Springer, 2006, pp. 404-417.
[43] E. Rublee, V. Rabaud, K. Konolige, G. Bradski, ORB: an efficient alternative to SIFT or SURF, in: Computer Vision (ICCV), 2011 IEEE International Conference on, IEEE, 2011, pp. 2564-2571.
[44] S. Belongie, J. Malik, J. Puzicha, Shape matching and object recognition using shape contexts, Pattern Analysis and Machine Intelligence, IEEE Transactionson, 24 (2002) 509-522.
[45] B. Allen, B. Curless, Z. Popović, Articulated body deformation from range scan data, in: ACM Transactions on Graphics (TOG), ACM, 2002, pp. 612-619.
[46] R. Cutler, M. Turk, View-based interpretation of real-time optical flow for gesture recognition, in: fg, IEEE, 1998, pp. 416.
[47] J.L. Barron, D.J. Fleet, S.S. Beauchemin, Performance of optical flow techniques, International journal of computer vision, 12 (1994) 43-77.
[48] C. Thurau, V. Hlaváč, Pose primitive based human action recognition in videos or still images, in: Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, IEEE, 2008, pp. 1-8.
[49] Q. Pu, S. Gupta, S. Gollakota, S. Patel, Whole-home gesture recognition using wireless signals, in: Proceedings of the 19th annual international conference on Mobile computing & networking, ACM, 2013, pp. 27-38.
[50] R. Ronfard, C. Schmid, B. Triggs, Learning to parse pictures of people, in: Computer Vision-ECCV 2002, Springer, 2002, pp. 700-714.
[51] S.-J. Lee, C.-S. Ouyang, S.-H. Du, A neuro-fuzzy approach for segmentation of human objects in image sequences, Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on, 33 (2003) 420-437.
[52] D. Tang, H.J. Chang, A. Tejani, T.-K. Kim, Latent regression forest: Structured estimation of 3d articulated hand posture, in: Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, IEEE, 2014, pp. 3786-3793.
[53] J. Han, L. Shao, D. Xu, J. Shotton, Enhanced computer vision with microsoft kinect sensor: A review, Cybernetics, IEEE Transactions on, 43 (2013) 1318-1334.
[54] Y. Yao, Y. Fu, Real-time hand pose estimation from RGB-D sensor, in: Multimedia and Expo (ICME), 2012 IEEE International Conference on, IEEE, 2012, pp. 705-710.
[55] I. Oikonomidis, N. Kyriazis, A.A. Argyros, Efficient model-based 3D tracking of hand articulations using Kinect, in: BMVC, 2011, pp. 3.
[56] J. Taylor, J. Shotton, T. Sharp, A. Fitzgibbon, The vitruvian manifold: Inferring dense correspondences for one-shot human pose estimation, in: Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, IEEE, 2012, pp. 103-110.
[57] Y. Li, Hand gesture recognition using Kinect, in: Software Engineering and Service Science (ICSESS), 2012 IEEE 3rd International Conference on, IEEE, 2012, pp. 196-199.
[58] M. Ye, X. Wang, R. Yang, L. Ren, M. Pollefeys, Accurate 3d pose estimation from a single depth image, in: Computer Vision (ICCV), 2011 IEEE International Conference on, IEEE, 2011, pp. 731-738.
[59] X. Zhang, X. Chen, W.-h. Wang, J.-h. Yang, V. Lantz, K.-q. Wang, Hand gesture recognition and virtual game control based on 3D accelerometer and EMG sensors, in: Proceedings of the 14th international conference on Intelligent user interfaces, ACM, 2009, pp. 401-406.
[60] D. Comaniciu, V. Ramesh, P. Meer, Real-time tracking of non-rigid objects using mean shift, in: Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE Conference on, IEEE, 2000, pp. 142-149.
[61] S. Thrun, W. Burgard, D. Fox, Probabilistic robotics, MIT press, 2005.
[62] R.E. Kalman, A new approach to linear filtering and prediction problems, Journal of Fluids Engineering, 82 (1960) 35-45.
[63] S. Haykin, Kalman filtering and neural networks, John Wiley & Sons, 2004.
[64] E. Wan, R. Van Der Merwe, The unscented Kalman filter for nonlinear estimation, in: Adaptive Systems for Signal Processing, Communications, and Control Symposium 2000. AS-SPCC. The IEEE 2000, IEEE, 2000, pp. 153-158.
[65] K. Okuma, A. Taleghani, N. De Freitas, J.J. Little, D.G. Lowe, A boosted particle filter: Multitarget detection and tracking, in: Computer Vision-ECCV 2004, Springer, 2004, pp. 28-39.
[66] S. Oron, A. Bar-Hillel, D. Levi, S. Avidan, Locally orderless tracking, in: Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, IEEE, 2012, pp. 1940-1947.
[67] J. Kwon, K.M. Lee, Tracking by sampling trackers, in: Computer Vision (ICCV), 2011 IEEE International Conference on, IEEE, 2011, pp. 1195-1202.
[68] J. Kwon, K.M. Lee, F.C. Park, Visual tracking via geometric particle filtering on the affine group with optimal importance functions, in: Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, IEEE, 2009, pp. 991-998.
[69] R. Gao, L. Wang, R. Teti, D. Dornfeld, S. Kumara, M. Mori, M. Helu, Cloud-enabled prognosis for manufacturing, CIRP Annals-Manufacturing Technology, 64 (2015) 749-772.
[70] T. Li, S. Sun, T.P. Sattar, J.M. Corchado, Fight sample degeneracy and impoverishment in particle filters: A review of intelligent approaches, Expert Systems with applications, 41 (2014) 3944-3954.
[71] T. Li, T.P. Sattar, S. Sun, Deterministic resampling: unbiased sampling to avoid sample impoverishment in particle filters, Signal Processing, 92 (2012) 1637-1645.
[72] J.M.D. Rincón, D. Makris, C.O. Uruňuela, J.-C. Nebel, Tracking human position and lower body parts using Kalman and particle filters constrained by human biomechanics, Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on, 41 (2011) 26-37.
[73] D.A. Ross, J. Lim, R.-S. Lin, M.-H. Yang, Incremental learning for robust visual tracking, International Journal of Computer Vision, 77 (2008) 125-141.
[74] Z. Kalal, J. Matas, K. Mikolajczyk, Pn learning: Bootstrapping binary classifiers by structural constraints, in: Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, IEEE, 2010, pp. 49-56.
[75] B. Babenko, M.-H. Yang, S. Belongie, Visual tracking with online multiple instance learning, in: Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, IEEE, 2009, pp. 983-990.
[76] A.W. Smeulders, D.M. Chu, R. Cucchiara, S. Calderara, A. Dehghan, M. Shah, Visual tracking: an experimental survey, Pattern Analysis and Machine Intelligence, IEEE Transactions on, 36 (2014) 1442-1468.
[77] L.E. Peterson, K-nearest neighbor, Scholarpedia, 4 (2009) 1883.
[78] A.D. Wilson, A.F. Bobick, Hidden Markov models for modeling and recognizing gesture under variation, International Journal of Pattern Recognition and Artificial Intelligence, 15 (2001) 123-160.
[79] A.D. Wilson, A.F. Bobick, Parametric hidden markov models for gesture recognition, Pattern Analysis and Machine Intelligence, IEEE Transactions on, 21 (1999) 884-900.
[80] S. Lu, J. Picone, S. Kong, Fingerspelling Alphabet Recognition Using A Two-level Hidden Markov Model, in: Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV), The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), 2013, pp. 1.
[81] J. McCormick, K. Vincs, S. Nahavandi, D. Creighton, S. Hutchison, Teaching a Digital Performing Agent: Artificial Neural Network and Hidden Markov Mode for recognising and performing dance movement, in: Proceedings of the 2014 International Workshop on Movement and Computing, ACM, 2014, pp. 70
[82] S.-Z. Yu, Hidden semi-Markov models, Artificial Intelligence, 174 (2010) 215-243.
[83] L.R. Rabiner, A tutorial on hidden Markov models and selected applications in speech recognition, Proceedings of the IEEE, 77 (1989) 257-286
[84] M.A. Hearst, S.T. Dumais, E. Osman, J. Platt, B. Scholkopf, Support vector machines, Intelligent Systems and their Applications, IEEE, 13 (1998) 18-28
[85] B. Schölkopf, A. Smola, Support Vector Machines, Encyclopedia of Biostatistics, (1998)
[86] M.E. Tipping, Sparse Bayesian learning and the relevance vector machine, The journal of machine learning research, 1 (2001) 211-244.
[87] B. Schiilkopf, The kernel trick for distances, in: Advances in Neural Information Processing Systems 13: Proceedings of the 2000 Conference, MIT Press, 2001, pp. 301.
[88] A. Cenedese, G.A. Susto, G. Belgioioso, G.I. Cirillo, F. Fraccaroli, Home Automation Oriented Gesture Classification From Inertial Measurements, Automation Science and Engineering, IEEE Transactions on, 12 (2015) 1200-1210.
[89] K.-p. Feng, F. Yuan, Static hand gesture recognition based on HOG characters and support vector machines, in: Instrumentation and Measurement, Sensor Network and Automation (IMSNA), 2013 2nd International Symposium on, IEEE, 2013, pp. 936-938.
[90] D. Ghimire, J. Lee, Geometric feature-based facial expression recognition in image sequences using multi-class adaboost and support vector machines, Sensors, 13 (2013) 7714-7734.
[91] O. Patsadu, C. Nukoolkit, B. Watanapa, Human gesture recognition using Kinect camera, in: Computer Science and Software Engineering (JCSSE), 2012 International Joint Conference on, IEEE, 2012, pp. 28-32.
[92] Y. Freund, R.E. Schapire, A decision-theoretic generalization of on-line learning and an application to boosting, Journal of computer and system sciences, 55 (1997) 119-139.
[93] R.E. Schapire, The boosting approach to machine learning: An overview, in: Nonlinear estimation and classification, Springer, 2003, pp. 149-171.
[94] P. Viola, M. Jones, Robust real-time object detection, International Journal of Computer Vision, 4 (2001) 51-52.
[95] A.S. Micilotta, E.-J. Ong, R. Bowden, Detection and Tracking of Humans by Probabilistic Body Part Assembly, in: BMVC, 2005.
[96] S. Celebi, A.S. Aydin, T.T. Temiz, T. Arici, Gesture Recognition using Skeleton Data with Weighted Dynamic Time Warping, in: VISAPP (1), 2013, pp. 620-625.
[97] T. Arici, S. Celebi, A.S. Aydin, T.T. Temiz, Robust gesture recognition using feature pre-processing and weighted dynamic time warping, Multimedia Tools and Applications, 72 (2014) 3045-3062.
[98] E.J.Keogh, M.J. Pazzani, Derivative Dynamic Time Warping, in: SDM, SIAM, 2001, pp. 5-7.
[99] S.S. Rautaray, A. Agrawal, Vision based hand gesture recognition for human computer interaction: a survey, Artificial Intelligence Review, 43 (2015) 1-54.
[100] S.S.Haykin, S.S. Haykin, S.S. Haykin, S.S. Haykin, Neural networks and learning machines, Pearson Education Upper Saddle River, 2009.
[101] T.H.H. Maung, Real-time hand tracking and gesture recognition system using neural networks, World Academy of Science, Engineering and Technology, 50 (2009) 466-470.
[102] H. Hasan, S. Abdul-Kareem, Static hand gesture recognition using neural networks, Artificial Intelligence Review, 41 (2014) 147-181.
[103] T. D'Orazio, G. Attolico, G. Cicirelli, C. Guaragnella, A Neural Network Approach for Human Gesture Recognition with a Kinect Sensor, in: ICPRAM, 2014, pp. 741-746.
[104] A. El-Baz, A. Tolba, An efficient algorithm for 3D hand gesture recognition using combined neural classifiers, Neural Computing and Applications, 22 (2013) 1477-1484.
[105] K. Subramanian, S. Suresh, Human action recognition using meta-cognitive neuro-fuzzy inference system, International journal of neural systems, 22 (2012) 1250028.
[106] Z.-H. Zhou, J. Wu, W. Tang, Ensembling neural networks: many could be better than all, Artificial intelligence, 137 (2002) 239-263.
[107] Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015) 436-444.
[108] J. Schmidhuber, Deep learning in neural networks: An overview, Neural Networks, 61 (2015) 85-117.
[109] J. Tompson, M. Stein, Y. Lecun, K. Perlin, Real-time continuous pose recovery of human hands using convolutional networks, ACM Transactions on Graphics (TOG), 33 (2014) 169.
[110] K. Simonyan, A. Zisserman, Two-stream convolutional networks for action recognition in videos, in: Advances in Neural Information Processing Systems, 2014, pp. 568-576.
[111] J. Nagi, F. Ducatelle, G. Di Caro, D. Cireşan, U. Meier, A. Giusti, F. Nagi, J. Schmidhuber, L.M. Gambardella, Max-pooling convolutional neural networks for vision-based hand gesture recognition, in: Signal and Image Processing Applications (ICSIPA), 2011 IEEE International Conference on, IEEE, 2011, pp. 342-347.
[112] A. Jain, J. Tompson, Y. LeCun, C. Bregler, Modeep: A deep learning framework using motion features for human pose estimation, in: Computer Vision--ACCV 2014, Springer, 2014, pp. 302-315.
[113] S. Bilal, R. Akmeliawati, A.A. Shafie, M.J.E. Salami, Hidden Markov model for human to computer interaction: a study on human hand gesture recognition, Artificial Intelligence Review, 40 (2013) 495-516.
[114] M.K. Brown, L.R. Rabiner, Dynamic time warping for isolated word recognition based on ordered graph searching techniques, in: Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP'82., IEEE, 1982, pp. 1255-1258.
[115] C.A. Ratanamahatana, E. Keogh, Everything you know about dynamic time warping is wrong, in: Third Workshop on Mining Temporal and Sequential Data, Citeseer, 2004.
[116] J.V. Tu, Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes, Journal of clinical epidemiology, 49 (1996) 1225-1231.