")
")
Аннотация
Жесты рук являются одним из основных средств бесконтактной связи между человеком и машинами. Существует большой интерес в управлении электронным оборудованием в хирургических кабинетах при помощи жестов для сокращения времени операций и снижения вероятности заражения. Существуют проблемы при внедрении систем распознавания жестов рук. Системы должны выполнять требования высокой точности и быстроты реакции. В этой статье мы представляем систему распознавания жестов рук на основе глубокого обучению. Глубокое обучение известно как точная модель обнаружения, но его высокая сложность не позволяет его использовать как компонент встроенной системы. Чтобы справиться с этой проблемой, мы применили некоторые изменения в структуре нашей работы для понижения уровня сложности. В результате предлагаемый метод может быть реализован в простой встроенной системе. Наши эксперименты показывают, что предлагаемая система способствует повышению точности и имеет меньшую сложность по сравнению с существующими методами.
Hand Gesture Recognition for Contactless Device Control in Operating Rooms.
Источник: researchgate.net
Перевод: Поткин О.А. (
1.Введение
Коммуникации с электронными устройствами без использования рук — открытая проблема, которая имеет множество требований. Удобство и поддержание гигиенических стандартов являются наиболее важными требованиями такой системы. Данная область исследований стала интересной особенно в перспективе использования в хирургических кабинетах для помощи хирургам, которые смогут сохранять свои руки в стерильном состоянии. Примером является система «Gestix», медицинский прибор, состоящий из большого дисплея для просмотра изображения МРТ. Он получает управляющие команды от человека при помощи ручных жестов [1]. Важнейшим преимуществом этой системы является то, что руки хирургов и вспомогательного персонала сохраняют стерильность во время операции. Другой пример применения ручных жестов в хирургических кабинетах предлагается в [2]. Авторы в [2] реализуют систему распознавания жестов рук для управления роботом под названием «Gestonurse». Этот робот отвечает за доставку хирургических инструментов во время операции. Эксперименты проводились в [3] и привели к выводу, что команды жестов рук быстрее и точнее, чем голосовые команды вспомогательному персоналу (например, медсестре). Другая работа в [3] предлагает систему управления освещением в операционной. Важнейшими преимуществами этой системы являются возможность работы с системой отслеживания рук и управление устройством, не касаясь нестерильных выключателей.
Взаимодействие хирургов или персонала больниц с подобными устройствами без использование клавиатуры или мыши (которые являются распространенными объектами распространения инфекций) также поддерживает стандарты гигиены в больничных и хирургических кабинетах. Голосовая команда — это еще один тип бесконтактной связи, но такие команды являются дискретными, а жестами рук, в свою очередь, можно выполнять аналоговые команды [4]. Помимо этого, голосовые команды имеют и другие недостатки, такие как низкая точность из-за наличия шума в хирургических кабинетах [5]. Хотя кажется, что эти устройства полностью удовлетворяют требованиям рынка, их функциональность ограничена из-за небольшого количества поддерживаемых жестов [4]. Чтобы справиться с этой проблемой, предлагаются некоторые альтернативы, такие как двуручные жесты или комбинирование жестов рук с голосовыми командами. Пример того, из каких компонентов может состоять система управления на основе жестов рук, показан на рисунке 1, где хирург может управлять дисплеем, отображающим разные рентгеновские изображения.
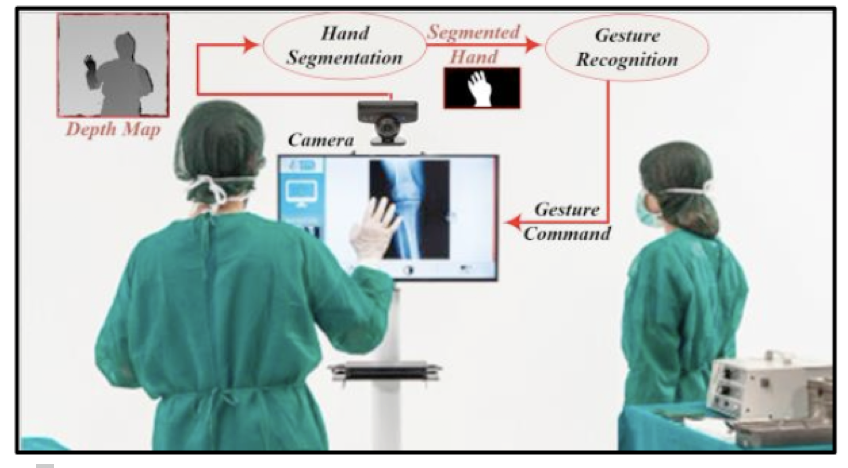
Рисунок 1: Глубина изображения используется для распознавания жестов руки хирурга. Фоновое изображение из [6].
Системы распознавания жестов рук обычно состоят из 3 этапов: обнаружение, отслеживание и распознавание [7]. Фаза обнаружения отвечает за сегментацию области руки. Входные данные для этой проблемы — глубина и цвет. На этапе отслеживания создается модель движения руки. Фаза отслеживания также используется для оценки характеристик и параметров, которые недоступны в высокоскоростной системе. Конечной и наиболее важной фазой распознавания жестов является фаза распознавания. Целью этого этапа является интерпретация команды, которую этот жест пытается передать. Фаза распознавания — открытая область исследования, и для решения этого вопроса предлагается множество исследований с различными подходами. В работе [8] применяется алгоритм граничного анализа для нахождения выпуклых точек. Эти выпуклые точки используются для обнаружения кончиков пальцев. В работе [9] используется технология машинного обучения на этапе распознавания. Механизм распознавания и метод опорных векторов (SVM) являются ключевыми структурами распознавания в этой системе. Другая работа в [10] в основном сосредоточена на обнаружении пальцев с учетом геометрии пальцев. Пальцы смоделированы как цилиндрические формы с параллельными линиями, и обнаруживаются как открытые, так и закрытые пальцы. Предлагаемая работа в [11] получает данные рук из трех устройств: Kinect, камера и датчик Leap Motion. Собранные данные помогают в создании некоторых геометрических признаков руки. Эти признаки включают в себя пальцы (угол, расстояние, высота и позиция кончика пальца), центр ладони, ориентация руки, гистограмма расстояния и кривизна контура руки. Признаки подаются в SVM для классификации и окончательного распознавания. Сложность и необходимость использования нескольких устройств являются недостатками этого метода. Предлагается несколько работ для решения проблемы распознавания жестов рук с помощью аппаратного обеспечения. В работе [12] была предложена архитектура для распознавания жестов на FPGA. Эта работа была сосредоточена на обнаружении кончиков пальцев на основе геометрии рук. На выходе этой системы демонстрировалось лишь количество открытых пальцев, что недостаточно для полноценной системы распознавания жестов рук.
Одной из важнейших задач исследователей в области ручных жестов является получение результатов в реальном времени. Но для систем реального времени требуются быстрые алгоритмы, которые нередко имеют низкую точность. Тем не менее, внедрение высокоточной системы распознавания жестов в реальном времени становится актуальным для такого места, как операционная. Одним из важных требований систем реального времени является простота интеграции во встроенную систему. Операционные системы, не относящиеся к системам реального времени, не заслуживают доверия для жизненно важных функций из-за их многозадачных структур и возможности прекращения их работы [13]. Встроенные системы обычно используются для устройств, которые выполняют только одну задачу. Они должны быть надежными и быстрыми. Хотя архитектура встроенной системы сложнее, чем реализация алгоритма на компьютере, преимущества встроенных систем перевешивают сложность процесса проектирования. Архитектура встроенной системы может основываться на программном обеспечении, использующем процессоры и микроконтроллеры, или на таком оборудовании, как FPGA и ASIC. Аппаратная реализация алгоритмов обработки изображений имеет много преимуществ по сравнению с программной реализацией [14]. Эти преимущества состоят в меньшем потреблении энергии, более быстрой скорости работы и повышенной надежности в шумных средах. Авторы [14] акцентируют внимание на замечательных аспектах обработки изображений на аппаратных средствах и использовании фильтров свертки для аппаратной реализации. Они показывают, что такая аппаратная реализация быстрее и имеет меньшую вычислительную сложность, чем программная реализация.
Методы глубокого обучения широко используются для решения различных задач распознавания образов [15, 16]. Сверточные нейронные сети (CNN) являются одним из самых мощных подходов к глубокому обучению, применимым в разных областях работы с изображениями. CNN могут использоваться как эффективный метод автоматического извлечения дискриминационных признаков из большого количества изображений. Недавно CNN продемонстрировали значительные улучшения в различных приложениях для медицинской визуализации [17-19] и особенно эффективны в распознавании и классификации различных структур. Это была основная причина, по которой мы решили реализовать такую сеть для распознавания разных жестов.
В этой статье мы предлагаем метод, основанный на глубоких нейронных сетях для решения проблемы распознавания жестов рук для приложений в хирургических кабинетах. На первом этапе нашей предлагаемой системы область руки детектируется и сегментируется как двоичная маска. Сегментация выполняется на основе информации о глубине, предоставляемой камерой. Бинарная карта, показывающая структуру руки, применяется к CNN. Для повышения эффективности CNN используется метод расширения доступных данных. CNN классифицирует изображения жестов в 10 определенных классов. Кроме того, применяется метод бинаризации сети. Бинаризация упрощает сеть для ее использования как компонента встроенной аппаратной системы. Экспериментальные результаты показывают, что наша предлагаемая система превосходит существующие сопоставимые методы с точки зрения точности распознавания и простоты реализации.
В оставшейся части этой статьи в разделе 2 объясняется предлагаемый метод распознавания ручных жестов. В разделе 3 представлены экспериментальные результаты. Вывод статьи приведен в разделе 4.
2.Предлагаемая система распознавания жестов
В этом разделе подробно обсуждается наш предложенный метод распознавания жестов рук. Предложенная система показана на рисунке 2. Ниже приводятся различные этапы описанного метода.
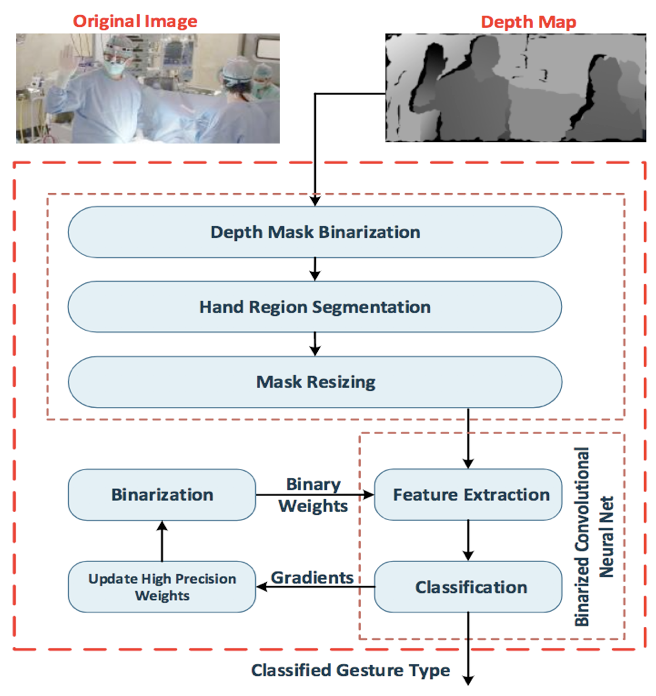
Рисунок 2: Блок-схема предлагаемого метода обучения. Пример изображения из [20].
2.1 Сегментация области руки
Первый этап распознавания разных жестов — это сегментация области руки во входном изображении. Для этой цели используется карта глубины, предусмотренная для изображений в наборе данных. Информация о глубине создается камерой, которая принимает изображения. Основная идея заключается в том, что рука человека ближе к камере по сравнению с другими частями тела.
На карте глубины области, которые ближе к камере, имеют более низкие значения. Также отмечается, что непроницаемые области имеют нулевые значения. Следовательно, чтобы обнаружить область руки, во-первых, нужно исключить окклюдированные области с нулевыми значениями из изображения. Затем рассматривается минимальное значение глубины в изображении, называемое m. Пиксель со значением m будет ближайшей точкой к камере. Так как в нормальных условиях рука человека, которая показывает жест, будет перед телом, точка с минимальным значением глубины будет находиться в области руки. Между тем, как правило, есть небольшие различия в глубине разных пикселей в области руки. Мы рассматриваем эти варианты как α. Следовательно, пиксели с глубиной, меньшей или равной пороговому значению T рассматриваются как T = m + α, обнаруживаются как рука и помечены как 1 в маске. Приведенная маска уточняется путем применения морфологических операций дилатации и заполнения отверстий. Отмеченная область в этом двоичном изображении будет включать область руки. Наконец, область руки выбирается как самый большой связанный компонент в этой бинарной маске, которая включает точку с минимальным значением глубины, m.
Используемый структурный элемент для операции расширения — это квадрат с длиной стороны = 3. В наших экспериментах α имеет значение 3. Некоторые образцы входных изображений, их соответствующие карты глубины и созданные ими макеты сегментации показаны на рисунке 3. Каждая приведенная бинарная маска показывает ручной жест вместе с локтем человека. Полученная маска будет применена к сверточной нейронной сети (далее CNN) с архитектурой, которая поясняется ниже.

Рисунок 3: Сегментация области руки для некоторых образцов изображений из набора данных. (a) изображение RGB, (b) карта глубины и (c) сегментированная область.
2.2 Архитектура CNN
Для распределения жестов на 10 классов используется двоичная маска, созданная на предыдущем этапе. Она подается на вход CNN, архитектура которой изображена на рисунке 4. Чтобы отправить изображение в нейронную сеть, сначала изображение должно быть изменено до размера 50 × 50 пикселей. Сеть состоит из слоев свертки (Conv1 и Conv2) и слоев максимального пула (Pool1 и Pool2). Порядок слоев в сети выглядит следующим образом: Conv1, Pool1, Conv2, Pool2.
В сверточных слоях все входное изображение свернуто с тем же фильтром. Это делается с целью извлечения одних и тех же признаков со всего изображения. Размер каждого ядра в первом сверточном слое Conv1 равен 5×5×1, а в этом слое 50 таких ядер. Второй сверточный слой, то есть Conv2, состоит из 20 ядер размером 3×3×50.
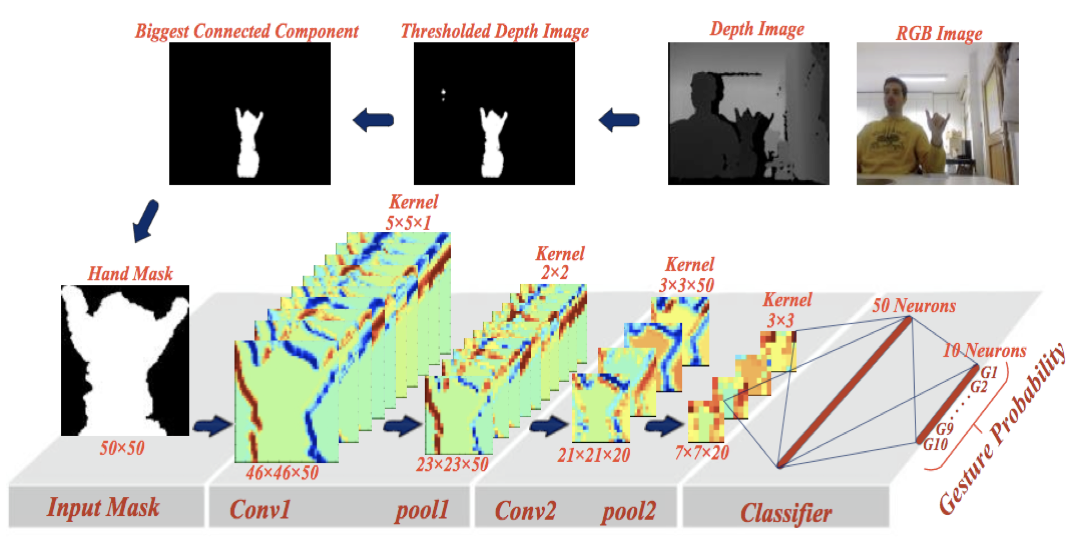
Рисунок 4: Архитектура сверточной нейронной сети
В CNN за сверточными слоями обычно следуют слои с максимальным пулом. Слои пула суммируют информацию, которая извлекается в предыдущих слоях и облегчают процедуру обучения. Размеры ядра в первом и втором слоях пула составляют 2×2 и 3×3 с шагом 2 и 3 соответственно. Это означает, что уровни Pool1 и Pool2 приводят к уменьшению их соответствующего входного размера на половину и 1/3.
Наконец, структура CNN завершается двумя полносвязными слоями: 50 нейронов в первом и 10 нейронах во втором слое. 10 нейронов в выходном слое создают вероятность принадлежности входного изображения к одному из 10 существующих классов жестов руки. Наибольшая вероятность указывает на класс жеста входного изображения.
Далее в этом разделе представлен способ упрощения нейронной сети для внедрения во встроенное аппаратное устройство, подходящее для хирургического кабинета.
2.3 Реализация встроенной системы
Следует отметить, что первый этап — сегментация области руки, достаточно прост для реализации в аппаратном устройстве. Основным проблемным местом здесь является сложность CNN, так как она содержит миллионы чисел и операций с плавающей запятой. Далее используется метод бинаризации сети. Результатом будет система, которая очень проста и может быть встроена в любое устройство.
Несмотря на высокую точность CNN, одним из недостатков использования этих сетей является то, что они содержат миллионы переменных, таких как веса ядер, которые необходимо сохранить. Кроме того, другая проблема заключается в том, что для вычисления выхода сети необходимо выполнить миллионы сложных операций с плавающей запятой. Например, для хранения Alex-net [21] требуется 249 МБ памяти, и для классификации только одного изображения через эту сеть должно выполняться 1,5 миллиона операций с плавающей запятой высокой точности. Для этого требуется высокопроизводительный сервер и подобная сеть не может быть реализована в устройстве с ограниченной вычислительной мощностью, поэтому сеть с данной архитектурой не может использоваться для приложений реального времени.
В последние годы было проведено множество исследований с целью упрощения CNN и сохранения качественных показателей сети [22, 23]. Одним из подходов для уменьшения размера сети и увеоичения ее скорости работы, является бинаризация весов сети на каждом уровне CNN. В этой статье мы используем метод, основанный на бинаризационном подходе [23] для внедрения нашей системы во встроенное аппаратное устройство.
Следует заметить, что в нашей сети есть два типа весов. Существуют весовые коэффициенты в сверточных слоях и веса в полносвязных слоях. Для бинаризации весов полносвязного слоя мы можем рассматривать его как сверточный слой. Следовательно, число ядер равно числу нейронов, а размер ядра будет равен размеру ввода. В результате все слои в сети будут рассматриваться как сверточные слои, а веса во всех слоях будут бинаризованы. Значения смещения (bias) не будут бинаризованы.
Метод бинаризации будет выполняться во время процедуры обучения. Так как рассчитанные различия для весов в каждом прогоне методом обратного распространения ошибки были бы небольшим числом. Бинаризация весов уменьшала бы эти рассчитанные значения и препятствовала процедуре обучения сети. Чтобы справиться с этой проблемой, значения с плавающей запятой весов будут храниться и обновляться во всех итерациях процедуры обучения. Бинаризация будет выполняться в начале аллитераций. Градиенты вычисляются на основе двоичных значений. Они используются для обновления весов, которые хранятся как числа с плавающей запятой. Эти значения сохраняются только во время процедуры обучения. На этапе развертывания бинаризованные значения будут храниться и использоваться. Следовательно, эти временные сохраненные значения с плавающей запятой не несут нагрузки при хранении сети.
Путем бинаризации весов во всех слоях сети емкость, необходимая для хранения сети, будет уменьшена с кратностью в 32. Кроме того, операция свертки будет выполняться на основе двоичных значений, что приведет к уменьшению сложности операции свертки. Так как веса бинаризованы, операции умножения для вычисления сверток будут выполняться путем сложения или вычитания. Это повысит скорость работы сети. При этом точность сети понижается на 3 процента.
3. Результаты эксперимента
Чтобы проверить нашу разработку, мы использовали общедоступный набор данных из [11]. Этот набор данных состоит из 10 жестов 14 человек. Каждый жест повторяется 10 раз каждым человеком с изменениями в направлении и положении руки. Следовательно, изначально в этом наборе данных было 1400 изображений. В целях совершенствования процедуры обучения исходный набор данных дополняется. С этой целью каждое изображение в наборе данных поворачивается от -20 до +20 градусов с интервалом 5 градусов. В результате в набор данных добавляются 8 новых изображений путем поворота каждого изображения под разными углами. В результате CNN обучается и тестируется с использованием 12 600 изображений. В тестовой фазе используются 9 различных поворотов изображения (8 оборотов плюс исходное изображение), и окончательная классификация выполняется на основе голосования между 9 полученными классами.
Расширенный набор данных случайным образом разделяется на 4 группы равного размера. В каждом прогоне одна группа остается в качестве теста, и обучение проводится на основе других 3 групп. Между тестом и данными для обучения нет совпадений, а изображения жестов каждого человека представлены только в одной группе. Следовательно, среди разных групп нет общего человека. CNN реализуется в Caffe [24], а метод Ксавье используется для инициализации весов и смещений. Тип решателя — стохастический градиентное спуск (SGD).
3.1 Обучение сверточной нейронной сети
Чтобы оценить процедуру обучения CNN, обученные ядра вместе с некоторыми образцовыми картами характеристик первого сверточного слоя представлены на рисунке 5. Сеть сходится, чтобы изучить некоторые функции из ориентированных на жесты входных масок руки. Например, можно видеть, что границы рук в разных направлениях выделены на картах функций. Из обученных ядер также можно сделать вывод, что сеть узнала некоторые функции, связанные с краями руки и пальцев. Следовательно, можно сказать, что CNN будет классифицировать изображения на основе структуры руки вдоль пальцев, извлеченных путем определения их границ.
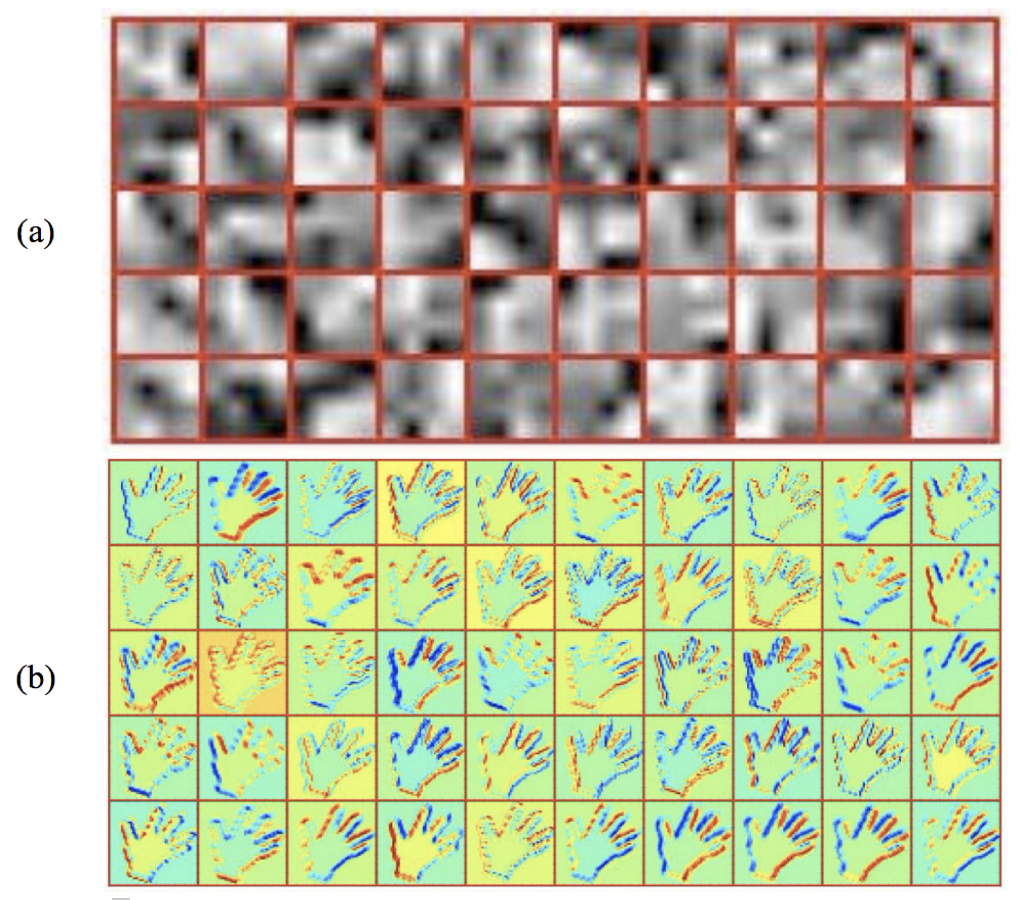
Рисунок 5: Обучение сверточной нейронной сети. (а) Исследуемые фильтры в первом сверточном слое и (б) карты характеристик образцов.
3.2 Результаты распознавания
Для оценки предлагаемой системы количественные результаты классификации, выполненной нашим методом, представлены на рисунке 6. Прежде всего, оценивается программная реализация нашего метода. Это версия, которую использует CNN на основе ее исходных значений с плавающей запятой, где веса не квантуются. Как видно, эта версия системы дает лучшие результаты по сравнению с [11]. Метод [11] — относительно сложный алгоритм распознавания жестов рук, который не достаточно прост для внедрения во встроенную систему.
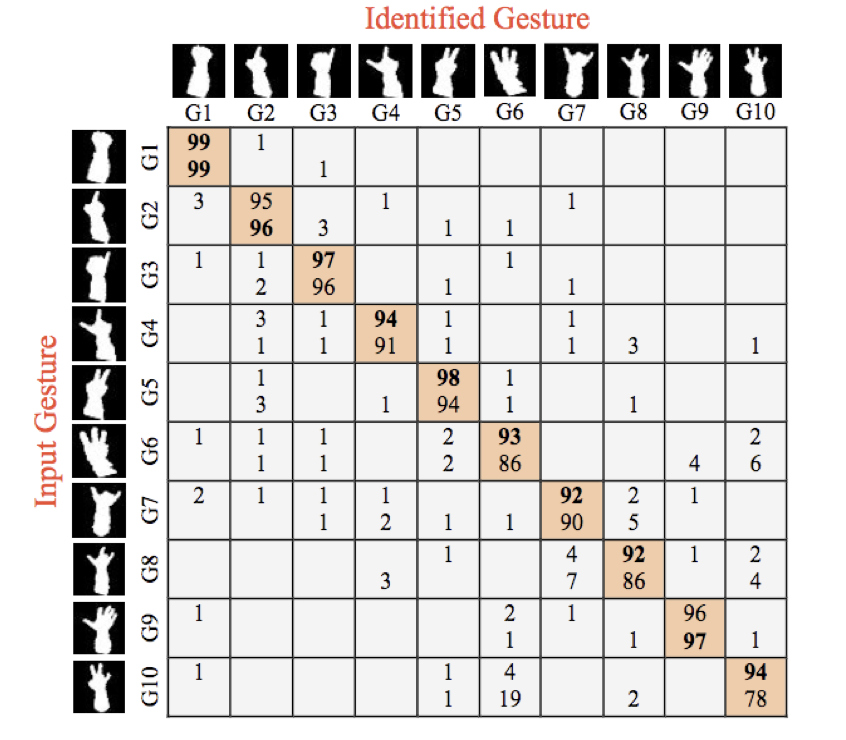
Рисунок 6: Количественное сравнение результатов распознавания жестов руки для 10 разных жестов. Верхние числа — это результаты нашего метода, а нижние числа — из [11].
Кроме того, также оценивается упрощенная версия нашего метода, где CNN бинаризуется. Выполняя бинаризацию, точность нашего метода уменьшается на 3%. Однако упрощенный метод является более желательным, поскольку его размер уменьшается, и он может работать быстрее. Следовательно, эта версия была бы пригодна для внедрения в аппаратное обеспечение как встроенная система в хирургическом кабинете. Несмотря на упрощение, на рисунке 7 видно, что наш метод по-прежнему превосходит другой метод с точки зрения точности классификации для большинства жестов.
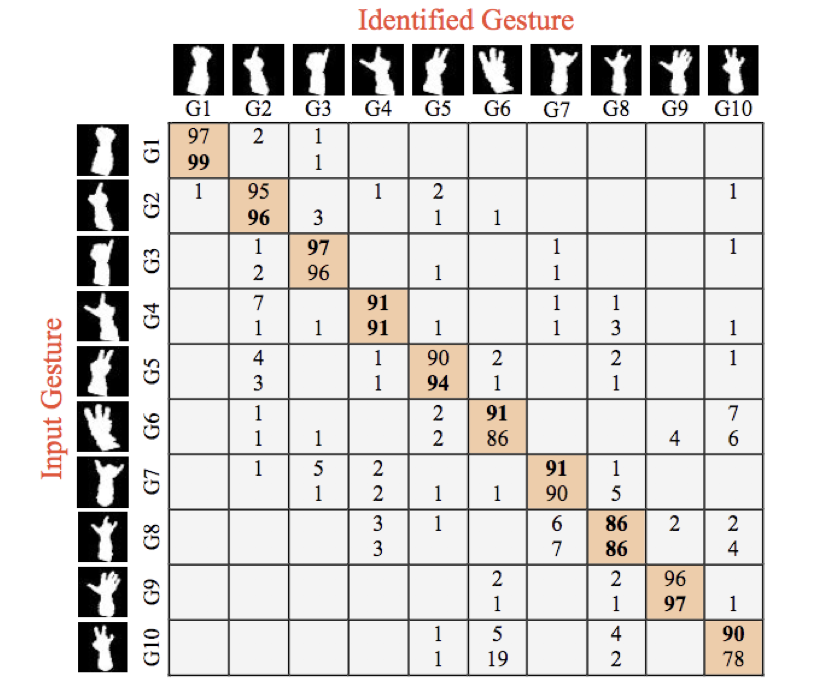
Рисунок 7: Количественное сравнение результатов распознавания жестов руки для 10 разных жестов. Верхние числа взяты из бинаризованной реализации нашего метода, а нижние числа — из [11].
В таблице 1 видно, что средняя точность классификации для разных жестов по нашему методу лучше, чем у других методов, как в сложной, так и в упрощенной версиях. Кроме того, следует заметить, что разница в точности для разных классов для наших метод ниже. Наш метод приводит к более надежной классификации для разных существующих классов жестов.
|
Метод |
Средняя точность |
Минимальная точность |
Отклонение |
|
[11] |
91.28 |
78 |
4.2 |
|
Предлагаемый программный метод |
94.86 |
92 |
0.65 |
| Предлагаемый бинаризованный метод |
92.07 |
86 |
1.4 |
Таблица 1: Сравнение общей эффективности методов распознавания жестов.
Наконец, чтобы завершить наш анализ, некоторые образцы изображений, которые неправильно классифицированы по нашему методу, представлены на рисунке 8. В некоторых из этих изображений жест, показанный человеком, не имеет точности, то есть человек не показывает должным образом жест. Кроме того, на некоторых изображениях, из-за положения руки, маска сегментации не смогла правильно извлечь структуру руки. Неточная маска сегментации также может ввести в заблуждение классификатор CNN.

Рисунок 8: Образцы неправильно классифицированных жестов. (a) Входное изображение, (b) карта глубины и (c) маска жеста.
4.Вывод
Существует множество преимуществ, если хирург может контролировать компьютерные дисплеи в операционной при помощи жестов. Это может эффективно снизить риск заражений. В этой статье мы показали, что точное распознавание жестов рук может быть достигнут путем глубокого обучения. Узким местом внедрения глубокого обучения в устройствах является высокая сложность этого метода. Мы предложили простую и точную реализацию глубокого обучения, подходящую для внедрения во встроенные системы. Мы протестировали наш метод на общедоступном наборе данных и сравнили наши результаты с существующим методом. Мы доказали, что, хотя наш метод прост, он имеет высокую точность.
Список литературы
-
Wachs , J.P., Kölsch, M., Stern, H., Edan, Y.: Vision-based hand-gesture applications. Communications of the ACM. 54, 60 (2011).
-
Jacob, M., Li, Y.-T., Akingba, G., Wachs, J.P.: Gestonurse: a robotic surgical nurse for handling surgical instruments in the operating room. Journal of Robotic Surgery. 6, 53–63 (2011).
-
Hartmann, F., Schlaefer, A.: Feasibility of touch-less control of operating room lights. International Journal of Computer Assisted Radiology and Surgery. 8, 259–268 (2012).
-
O'hara, K., Dastur, N., Carrell, T., Gonzalez, G., Sellen, A., Penney, G., Varnavas, A., Mentis, H., Criminisi, A., Corish, R., Rouncefield, M.: Touchless interaction in surgery. Communications of the ACM. 57, 70–77 (2014).
-
Wachs, J.P., Stern, H.I., Edan, Y., Gillam, M., Handler, J., Feied, C., Smith, M.: A Gesture-based Tool for Sterile Browsing of Radiology Images. Journal of the American MedicalInformatics Association. 15, 321–323 (2008).
-
progesoftware | Proge-Software, http://www.progesoftware.it
-
Rautaray, S.S., Agrawal, A.: Vision based hand gesture recognition for human computer interaction: a survey. Artificial Intelligence Review. 43, 1–54 (2012).
-
Lee, D., Park, Y.: Vision-based remote control system by motion detection and open finger counting. IEEE Transactions on Consumer Electronics. 55, 2308–2313 (2009).
-
Dardas, N.H., Georganas, N.D.: Real-Time Hand Gesture Detection and Recognition Using Bag-of-Features and Support Vector Machine Techniques. IEEE Transactions on Instrumentation and Measurement. 60, 3592–3607 (2011).
-
Zhou, Y., Jiang, G., Lin, Y.: A novel finger and hand pose estimation technique for real-time hand gesture recognition. Pattern Recognition. 49, 102–114 (2016).
-
Marin, G., Dominio, F., Zanuttigh, P.: Hand gesture recognition with leap motion and kinect devices. 2014 IEEE International Conference on Image Processing (ICIP). (2014).
-
Wang, R., Yu, Z., Liu, M., Wang, Y., Chang,Y.: Real-time visual static hand gesture recognition system and its FPGA-based hardware implementation. 2014 12th International Conference on Signal Processing (ICSP). (2014).
-
Stallings, W.: Operating system. Maxwell Macmillan Canada, New York (1992).
-
Wnuk, M.: Remarks on hardware implementation of image processing algorithms. International Journal of Applied Mathematics and Computer Science. 18.1, 105-110 (2008).
-
Schmidhuber, J.: Deep learning in neural networks: An overview. Neural Networks. 61, 85–117 (2015).
-
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature. 521.7553, 436–444 (2015).
-
Nasr-Esfahani, E., Samavi, S., Karimi, N., et all.: Vessel extraction in X-ray angiograms using deep learning. 2016 38th Annual International Conference of the IEEEEngineering in Medicine and Biology Society (EMBC), (2016).
-
Cireşan, D.C., Giusti, A., Gambardella, L.M., Schmidhuber, J.: Mitosis Detection in Breast Cancer Histology Images with Deep Neural Networks. Medical Image Computing and Computer-Assisted Intervention – MICCAI 2013 Lecture Notes in Computer Science. 411–418 (2013).
-
Nasr-Esfahani, E., Samavi, S., Karimi, N., et all.: Melanoma detection by analysis of clinical images using convolutional neural network. 2016 38th Annual Int Conf of the IEEE Engineering in Medicine and Biology Society (EMBC), (2016).
-
TEDCAS, http://www.tedcas.com
-
Krizhevsky, A., Sutskever, I., Hinton, G.: Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems. 1097–1105, (2012).
-
Courbariaux, M., Bengio, Y.: Binarynet: Training deep neural networks with weights and activations constrained to 1 or-1. arXiv preprint arXiv. 1602.02830, (2016).
-
Rastegari, M., Ordonez, V., Redmon, J., Farhadi, A.: XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. Computer Vision – ECCV 2016 Lecture Notes in Computer Science. 525–542, (2016).
-
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding. Proceedings of the ACM International Conference on Multimedia -MM '14. (2014)